
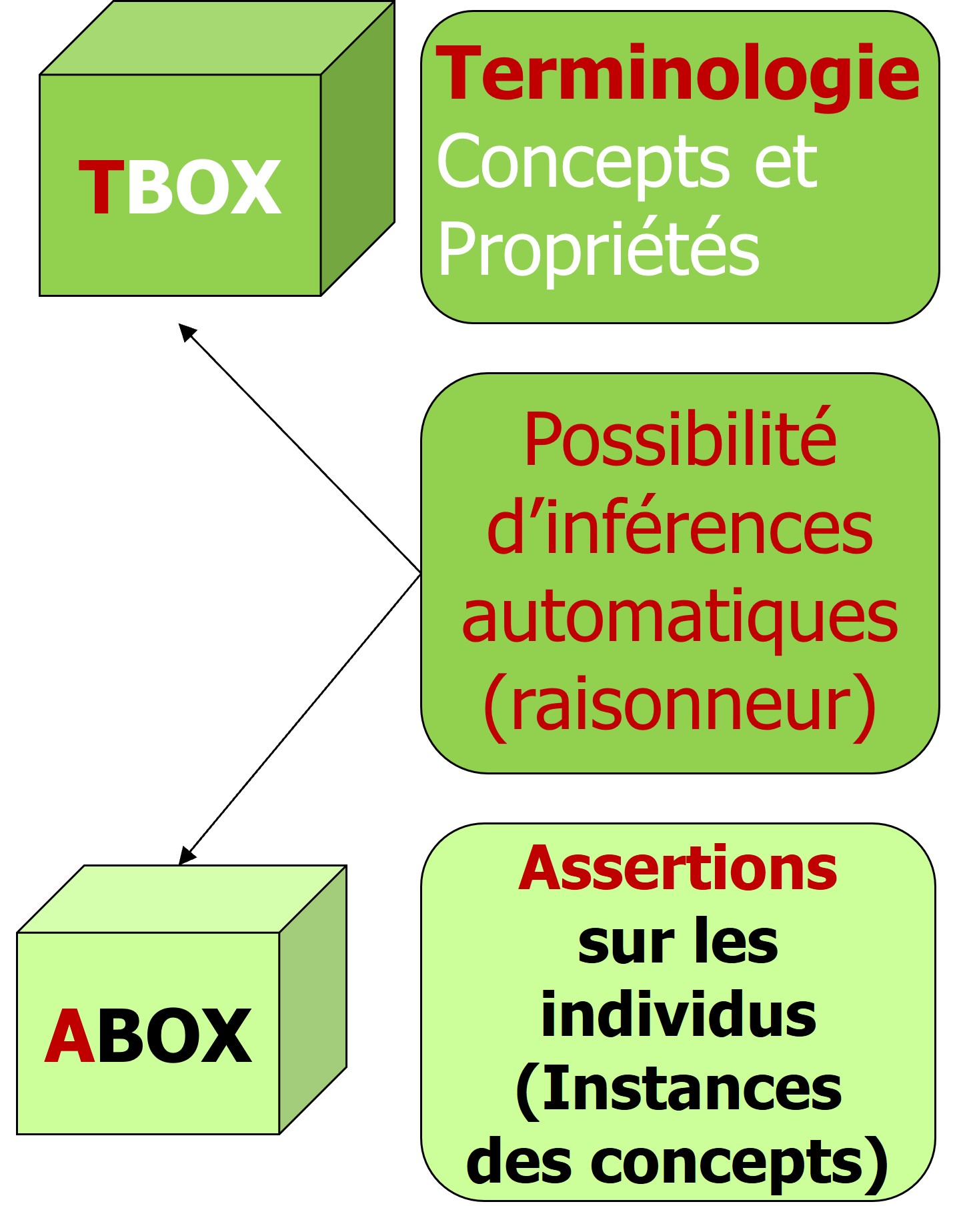
Une même TBox peut servir à plusieurs ABoxes différentes. C’est d’ailleurs le principe des Knowledge Graphs RDF avec des schémas OWL. On peut réconcilier plusieurs graphes dans un quad store, regroupant les triplets par graphes nommés pour étendre la base avec des sources multiples.
Une même TBox peut servir à plusieurs ABoxes différentes. C’est d’ailleurs le principe des Knowledge Graphs RDF avec des schémas OWL. On peut réconcilier plusieurs graphes dans un quad store, regroupant les triplets par graphes nommés pour étendre la base avec des sources multiples. Contrairement aux bases de données classiques où l’absence d’information implique le faux, dans un Knowledge Graph, tout peut être vrai tant qu’il n’est pas prouvé faux (hypothèse du monde ouvert).
Il faut donc explicitement formaliser ce que l’on sait être impossible.
Selon les auteurs de « LOVMI: vers une méthode interactive pour la validation d’ontologies » [1], la validation des ontologies demeure une question centrale de l’ingénierie des connaissances. Elle s’articule autour de deux problématiques complémentaires : (1) la validation structurelle et (2) la validation sémantique (de l’adéquation au domaine modélisé). Dans cet article, c’est essentiellement du deuxième point qu’il est question et de la nécessaire interaction humaine.
 La validation repose sur deux piliers :
La validation repose sur deux piliers :
-
1. La qualité de la construction: Gruber[2] a déterminé un premier jet de critères à vérifier pour la bonne conception des ontologies en 1993. Depuis, la pratique et la recherche ont pu mettre en avant d’autres critères de qualité pour la maintenabilité et aussi des aspects logiques pas toujours vérifiés par les raisonneurs. Un outil comme NEOntometrics propose de nombreuses métriques de qualité structurelles issues de la littérature (dont OntoQA[3]) et des métriques de cohésion et de complexité. Cet outil est associé à une ontologie[4] de définition desdites métriques. L’évaluation de la qualité technique structurelle de l’ontologie est une activité à part entière qui, pour être bien traité, fera l’objet d’un autre billet de bonnes pratiques.
-
2. L’usage recherché: L’ontologie doit répondre aux questions de ses futurs usagers (experts métier), et non seulement aux critères techniques des ontologues. C’est la distinction classique, dans le développement logiciel, entre vérification (le code fonctionne-t-il ?) et validation (la solution répond-elle au besoin ?).
Dans l’ingénierie du logiciel, il a fallu de nombreuses années et de nombreux échecs de projets pour s’apercevoir que la formulation des exigences était une condition sine qua non pour construire des solutions efficaces et de qualité. Il en est de même pour les ontologies.

La formalisation logique n’est pas une traduction du langage naturel en SPARQL, ni un simple exercice d’extraction de termes pour créer des concepts. L’objectif n’est pas de convertir mot à mot les questions de compétences en requêtes, ni de lister les termes pour les transformer en classes. Il s’agit d’une phase de spécification formelle exigeant une réflexion approfondie sur les implications logiques des questions et des réponses souhaitées. Cette étape soulève des interrogations cruciales
-
Quels sont les liens d’hyponymie, méronymie ou synonymie ?
-
Comment éviter les cycles hiérarchiques ?
-
Un terme désigne-t-il une instance ou un concept ?
-
Faut-il une propriété pour une énumération ou une classe dédiée pour plus de richesse sémantique ?
Le niveau de granularité dépend de l’usage. Si je veux une ontologie des vins, je n’irai pas au même niveau de granularité selon qu’il s’agisse de choisir un type de vin pour un plat, ou de gérer une cave avec la parcelle exacte de l’exploitant, l’année de chaque bouteille et les particularités de chaque année selon les régions. Voire je pourrais vouloir faire le distinguo entre régions et terroirs dans le second cas sans forcément en avoir besoin dans le premier.
Par ailleurs si dans le premier cas je peux me satisfaire d’une propriété pour lier un vin à une énumération de couleurs, pour répondre à une question du type «est-ce qu’un vin particulier est classé comme vin rouge », dans le second je peux vouloir créer une classe de couleurs de vin pour expliquer, par exemple, les propriétés des vins bleus ou oranges et répondre à une question du type: «à partir de quelles grappes sont constitués les vins de telle couleur»? Ou «quel procédé donne cette couleur à un vin ? ».

L’ontologue ne travaille pas seul. Les CQs nécessitent l’expertise des domaines concernés pour décrypter les concepts sous-jacents. Ce n’est pas une traduction automatique mais un creusement des implications de chaque question, où l’interaction humaine est clé. Car il s’agit d’éliciter une connaissance qui n’est pas, souvent, encore formalisée. De plus, il faut toujours se rappeler de l’usage qui est visé, pour éviter les écueils de la sur spécification ou sous-spécification qui ont si souvent miné les développements logiciels. Et les garants de l’usage sont ceux qui peuvent exprimer «à quoi ça sert», plutôt que «comment ça marche».
Le projet Beyond2022 pour la mise en place d’un Knowledge Graph en lien avec l’héritage culturel de l’Irlande [7] l’illustre bien. Les instructions aux historiens pour exprimer leurs attentes sous forme de questions auxquelles le KG devait répondre ont été délibérément maintenues vagues. «II a été estimé que cela était nécessaire, car beaucoup des historiens n’avaient pas travaillé avec des KG auparavant. Leur accorder un large degré de liberté a aidé l’équipe d’informatique non seulement à concevoir la structure du KG, mais aussi à percevoir comment les historiens le considéraient comme un outil de recherche. »
Dans ce cas d’usage 54 questions de compétences sont sorties de cette collaboration, qui ont ensuite été raffinées et priorisées … comme des exigences de projet logiciel.
Ce qui veut dire en d’autres termes que se poser les bonnes questions de compétences avec les parties prenantes plutôt que se fier aux compétences de l’ontologue seul reste toujours un préalable à toute solution pérenne.
Sabine Bohnké.