
Home / ingénierie des connaissances, KnowledgeGraph, ontologies / Pourquoi une « couche sémantique » ne remplace pas un raisonneur ontologique
Pourquoi une « couche sémantique » ne remplace pas un raisonneur ontologique
Pourquoi cette distinction est-elle critique en 2026 ?
Le terme « semantic layer » s’est imposé dans le marketing des plateformes de données telles que dbt, Looker, AtScale, Timbr.ai, Microsoft Fabric IQ, pour n’en citer que quelques-unes. Derrière cette étiquette commune se cachent des réalités architecturales radicalement différentes, allant du simple catalogue de métadonnées au moteur d’inférence en logique descriptive. Les confondre conduit à des choix d’architecture sous-optimaux et à des systèmes qui semblent sémantiques en surface, mais échouent à fournir la rigueur logique nécessaire à une IA fiable ou à une interopérabilité sémantique profonde.
Cet article distingue trois niveaux : la couche sémantique BI (mapping de données), l’ontologie formelle avec son raisonneur (validation logique), et les moteurs d’inférence à grande échelle (traitement des instances). Il examine pour chacun des outils disponibles en 2026, leur état de maintenance si nécessaire, et leurs limites respectives.
La couche sémantique BI : un catalogue de métadonnées enrichi, pas un raisonneur
Dans les limites bien documentées des premiers Data Lake figurait l’incapacité à qualifier la sémantique des données hétérogènes qui y affluaient. Ce qui a logiquement conduit les outils BI à intégrer des catalogues de données et des couches de virtualisation sémantique. Un tel catalogue d’entreprise est indéniablement une bonne pratique de gouvernance : relier des bases de données relationnelles disparates autour de définitions communes est une condition nécessaire à l’analyse décisionnelle cohérente.
Mais cette approche de mapping sémantique est fondamentalement différente du raisonnement automatique formel. Elle facilite la découverte et l’agrégation des données ; elle ne garantit pas l’interopérabilité sémantique au sens rigoureux du terme, c’est-à-dire :
- la désambiguation sémantique : accès sans ambiguïté à des assertions formellement définies et logiquement cohérentes, fondé sur des identifiants pérennes (IRI), des définitions formelles (pas de simples labels en langage naturel) et des relations explicites entre concepts (subsomption, équivalence, disjonction, entailment) ;
- l’actionabilité par déduction : capacité pour une machine à inférer automatiquement de nouveaux faits ou à déclencher des actions à partir de règles logiques validées. Ce qui va bien au-delà des jointures SQL ou des règles d’induction.
Pour qu’une machine détecte des incohérences, infère des classifications implicites ou valide la cohérence logique d’un ensemble de faits, il est impératif de construire des ontologies formelles en logique descriptive (typiquement OWL 2 DL) et de les soumettre à une chaîne de validation dédiée.
L'exemple d'« Employé » : du mapping à la modélisation correcte
Probleme:
Une modélisation naïve définit Employé comme une sous-classe de Personne : dans le système RH, ce serait une personne sous contrat actif ; dans le système Paie, toute personne ayant perçu au moins un salaire, y compris les anciens collaborateurs. Un outil de mapping fera coexister ces deux définitions sous le même label sans détecter la contradiction. Un raisonneur OWL, lui, la détectera si les deux définitions sont formellement spécifiées en deux classes disjointes : EmployéActif comme personne liée à un contrat en cours, AncienCollaborateur comme personne ayant perçu un salaire sur une appartenance terminée. La contradiction détectable par le raisonneur surgit précisément quand un outil de mapping les fait correspondre sous un même concept Employé sans distinction temporelle, posant ainsi implicitement leur équivalence.
Mais cette modélisation est elle-même ontologiquement discutable.
Solution:
Employé est une propriété anti-rigide au sens d’OntoClean : une personne peut cesser d’être employée sans cesser d’exister. Traiter Employé comme une sous-classe de Personne revient à confondre un rôle temporaire avec une propriété essentielle — une erreur que le raisonneur ne détectera pas si la contrainte n’est pas formalisée, mais qu’un audit OntoClean mettra en évidence.
La modélisation correcte introduit une classe distincte: Appartenance. Cette dernière relie une Personne à une Organisation pendant une période donnée, avec un rôle et un type de contrat. Employé devient alors non plus une catégorie de personnes, mais une catégorie d’appartenances actives sous contrat de travail. Un raisonneur peut alors déduire automatiquement : qui est actuellement employé, qui l’a été et quand, quels contrats se chevauchent, quelles incohérences temporelles existent et ce, sans qu’aucune de ces inférences ait besoin d’être programmée explicitement.
C’est précisément ce que ni une jointure SQL ni une couche sémantique BI ne peuvent accomplir de façon déclarative et générique.
Cet exemple illustre pourquoi il est essentiel de distinguer les outils selon leur capacité réelle de raisonnement. Examinons deux plateformes emblématiques pour vérifier cette hypothèse.
Ce que Fabric IQ et Timbr.ai ne font pas
Microsoft Fabric IQ / Ontology Playground
Fabric IQ repose sur un modèle de graphe à propriétés étiquetées (Labeled Property Graph) stocké dans OneLake, exposé via GQL (Graph Query Language, le nouveau standard ISO pour graphes à propriétés) et lié à des sources de données OneLake par data binding. L’Ontology Playground est un outil front-end pédagogique, une application JavaScript statique, sans backend, qui permet de visualiser et prototyper des ontologies, d’importer/exporter du RDF/XML pour compatibilité avec l’écosystème OWL, et de générer des pull requests vers un catalogue communautaire.
Il n’y a aucun raisonneur de logique descriptive dans cet écosystème. Les « contraintes» évoquées dans la documentation sont des vérifications de qualité des données (nullabilité, plages, unicité) et des règles déclenchement-action via Fabric Activator. Ce ne sont pas des vérifications de cohérence TBox ni de satisfaisabilité de classes. Pour valider logiquement une ontologie prototypée dans l’Ontology Playground, il faut l’exporter en OWL et l’ouvrir dans Protégé avec HermiT ou Openllet.
Timbr.ai
Timbr.ai se positionne comme une couche sémantique SQL : son cœur est un moteur de réécriture de requêtes (SQL rewrite engine) qui traduit des ontologies définies en DDL SQL étendu (Data Definition Language) et exportables en OWL pour interopérabilité, en vues SQL et JOIN automatiques sur les sources relationnelles sous-jacentes (Snowflake, Databricks, Azure, etc.). Les inférences disponibles (héritage de classes, quelques règles de propriétés) sont implémentées comme des transformations SQL déterministes, sans garantie de complétude logique formelle.
Il n’y a pas de vérification de cohérence TBox, pas de détection d’insatisfaisabilité, pas de raisonnement en monde ouvert (Open World Assumption). Timbr opère sous les hypothèses du monde fermé relationnel : l’absence d’un fait est une absence de donnée, non une inférence. Toute validation ontologique formelle est par construction extérieure à cet outil.
Ces deux plateformes répondent à des besoins concrets et légitimes d’unification et d’interrogation des données d’entreprise. Elles ne sont simplement pas des environnements de raisonnement formel en logique descriptive, et ne sauraient en tenir lieu.
La chaîne de validation formelle : TBox et ABox, deux niveaux distincts
La validation logique d’une base de connaissance reposant sur une ontologie formelle se décompose en deux niveaux qui ne mobilisent pas les mêmes outils.
Validation de la TBox : les raisonneurs à tableau
La TBox (Terminological Box) est la partie schématique de l’ontologie : définitions de classes, propriétés, axiomes, restrictions. Sa validation exige un raisonneur à tableau (algorithme de tableau), qui construit de façon exhaustive les modèles possibles de la théorie pour détecter :
- les classes insatisfiables (ne pouvant avoir aucune instance dans aucune interprétation) ;
- les incohérences globales (contradictions entre axiomes) ;
- les subsomptions implicites (hiérarchies non déclarées mais déductibles).
Cette approche est la seule garantissant la décidabilité et la complétude formelle pour OWL 2 DL (SROIQ), au prix d’une complexité élevée 2-NEXPTIME pour OWL 2 DL complet, ce qui rend le raisonnement combiné TBox+ABox impraticable dès que l’ABox dépasse quelques dizaines de milliers d’instances non triviales.
État des raisonneurs OWL à tableau en 2026
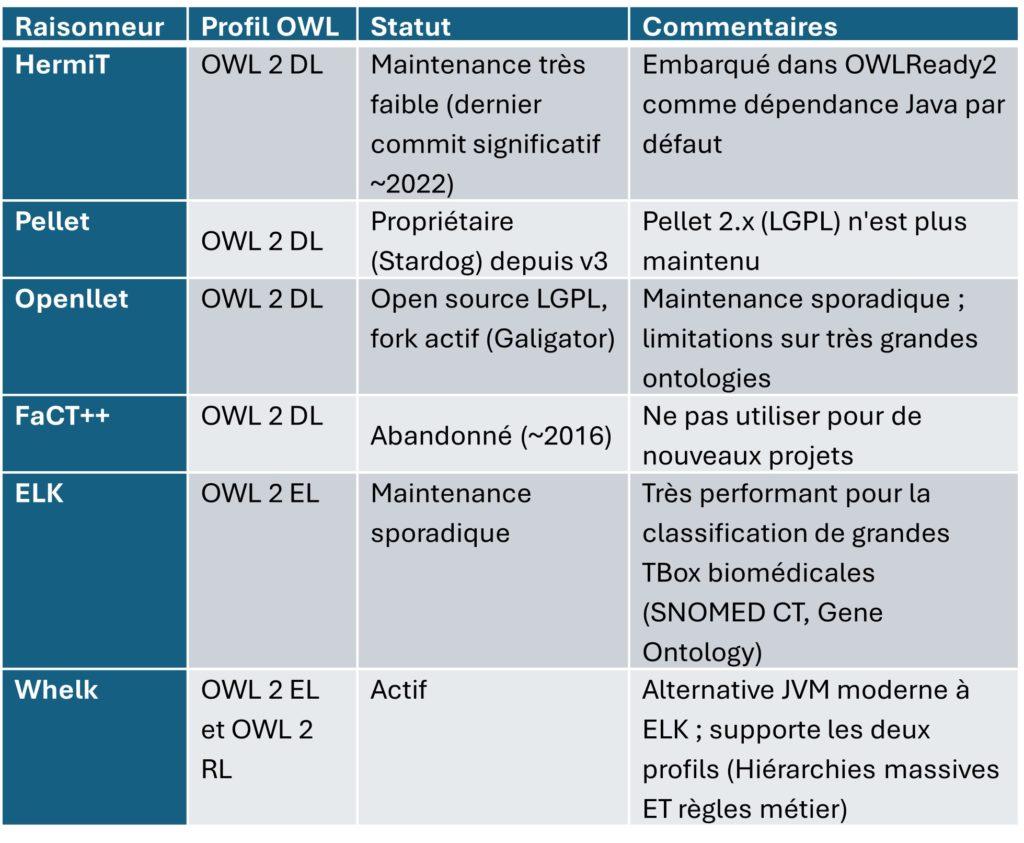
Le constat du tableau 1 est clair : l’écosystème open source des raisonneurs OWL tableau souffre d’un relatif abandon. Pour les projets industriels nécessitant la pleine expressivité d’OWL 2 DL, Protégé + HermiT (ou Openllet) reste la combinaison de référence pour la validation TBox, malgré le manque de dynamisme de ces projets. Pour les ontologies OWL 2 EL (biomédicales principalement), ELK ou Whelk offrent des performances nettement supérieures.
Note : Whelk supporte également OWL 2 RL
, ce qui le rend plus polyvalent qu’ELK pour les cas combinant hiérarchies massives et règles métier.Validation et inférence sur l'ABox : les moteurs Datalog
L’ABox (Assertion Box) contient les instances : les faits individuels qui peuplent la base de connaissance, en l’occurrence le Knowledge Graph RDF si on utilise les standards du W3C. Ainsi que vu précédemment, dès que l’ABox dépasse quelques dizaines de milliers d’instances non triviales, la complexité des algorithmes de tableau rend le temps de calcul incompatible avec toute contrainte opérationnelle raisonnable : le raisonneur termine en théorie, mais dans un temps qui le rend inutilisable en pratique industrielle.
L’industrie a dès lors convergé vers des profils OWL restreints, notamment OWL 2 RL (règles) et OWL 2 EL (hiérarchies massives, typiquement biomédicales) dont les fragments sont traductibles en règles Datalog, permettant un raisonnement par chaînage avant (matérialisation) ou réécriture de requête, beaucoup plus scalables.
Matérialisation vs réécriture de requêtes
- Matérialisation (forward chaining) : les triplets inférés sont calculés en amont et stockés physiquement. Les requêtes portent sur le graphe augmenté. Avantage : requêtes très rapides. Inconvénient : surcoût de stockage, maintenance des inférences coûteuse lors des mises à jour (rétractation de triplets inférés en cascade). Outils : RDFox (matérialisation parallèle en mémoire vive, le plus rapide), GraphDB (propose un moteur natif très rapide pour RDFS-Plus (profil léger) et un moteur complet pour OWL 2 RL), Stardog (via son moteur Stride, en cours de maturation).
- Réécriture de requête (backward chaining / query-time) : aucun triplet inféré n’est stocké ; la requête SPARQL est réécrite à l’exécution en tenant compte des axiomes. Avantage : données toujours fraîches, compatible avec les virtual graphs. Inconvénient : la réécriture peut générer des requêtes exponentiellement plus grandes pour des hiérarchies profondes. Outils : Stardog (mode Blackout, le moteur natif le plus mature et performant pour RL/EL), Ontop/Ontopic Studio.
Cependant, pour la majorité des cas d’usage entreprise (hors recherche fondamentale ou systèmes critiques dans la défense ou la pharmacie), ces moteurs RL/EL suffisent.
À condition de ne pas leur demander ce que seul un raisonneur à tableau peut faire, et d’assembler la chaîne en conséquence.
Bonne pratique : assembler la chaîne
Aucun outil disponible en 2026 ne couvre l’intégralité de la chaîne de validation formelle des Knowledge Graphs. La bonne pratique consiste à assembler des briques complémentaires selon les besoins :
- Validation logique de la TBox -> Protégé + HermiT ou Openllet (OWL 2 DL complet) ; ELK ou Whelk pour les ontologies OWL 2 EL à grande échelle.
- Vérification des anti-patterns de modélisation -> OOPS! (Ontology Pitfall Scanner) : 40 catégories de pièges détectés automatiquement, niveaux Critical / Important / Minor. Exemples : création de synonymes comme des classes distinctes, confusion entre classe et instance, propriétés inverses non déclarées, inclusion de cycles dans la hiérarchie …
- Métriques de qualité structurelle ->NEOntometrics (GraphQL API) . Exemples : tangledness (enchevêtrement de la hiérarchie), branching factor (largeur moyenne des ramifications), profondeur de l’arbre d’héritage, métriques OQuaRE.
- Conformité FAIR pour la publication-> FOOPS! : vérification des identifiants pérennes, métadonnées de provenance, licences, annotations multilingues.
- Inférence et requêtage à grande échelle sur l’ABox -> RDFox (OWL 2 RL, matérialisation parallèle in-memory), Stardog (réécriture de requête, virtual graphs), GraphDB (OWL 2 RL, matérialisation, SPARQL fédéré).
- Validation de contraintes sur l’ABox -> SHACL (standard W3C) : validation déclarative de formes (shapes) sur les instances, supporté nativement par GraphDB, Stardog et PySHACL. Complémentaire du raisonnement OWL, SHACL cible les violations de règles métier (cardinalités, types, domaines) que le raisonneur ne détecte pas forcément.
- Validation fonctionnelle par questions de compétence (CQs) ->Les CQs sont des exigences fonctionnelles exprimées en langage naturel avant toute décision de modélisation : elles définissent ce que l’ontologie doit être capable de représenter et de raisonner, sans présupposer de choix de classes ou de propriétés. Les formaliser prématurément en SPARQL reviendrait à modéliser pour répondre à une requête plutôt que pour représenter fidèlement le domaine. Ce n’est qu’une fois la TBox stabilisée et validée logiquement qu’elles peuvent être traduites en requêtes SPARQL-OWL pour constituer une suite de tests de régression fonctionnelle (cf. bonne pratique ontologique n°2 : des questions de compétences).
Savoir assembler ces briques, sans confondre chacune d’elles avec une couche sémantique BI « tout-en-un », est précisément ce qui distingue une ingénierie ontologique rigoureuse d’un habillage marketing.
Ce que cet article ne traite pas encore
La validation d’une ontologie dépasse la cohérence logique. Deux dimensions complémentaires seront traitées dans les articles suivants de cette série :
- La qualité méta-ontologique de la TBox : au-delà de la cohérence formelle, une ontologie peut être logiquement valide et sémantiquement inadéquate. Les méthodes comme OntoClean (identité, rigidité, unité des classes), les Ontology Design Patterns et les métriques OQuaRE permettent d’évaluer cette dimension.
- Le choix des plateformes de Knowledge Graph pour l’ABox : les critères architecturaux (virtualisation vs matérialisation, profil OWL supporté, SWRL, SHACL, fédération SPARQL) en fonction des cas d’usage industriels.
.