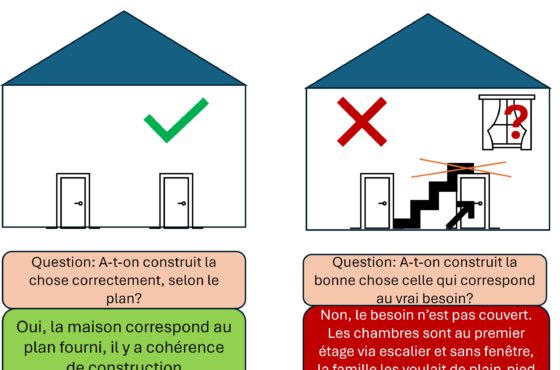
Intelligence Machine et Knowledge Graphs
Qu’est-ce qu’on appelle Intelligence Artificielle, in fine ? Les deux mots accolés ne conduisent qu’à des définitions bancales ou à un oxymore. Une machine de type système informatique, exécutant des algorithmes, n’a ni intelligence ni sentience. Pas plus qu’un texte ou des paroles n’évoquent d’expériences à ses sens absents, elle n’a de raisonnements poussés. Néanmoins, on peut lui donner la capacité à associer un sens explicite à des mots, dans le contexte où ils sont exprimés.

Kundera – couverture de la traduction française révisée avec note de l’auteur de 1985
L’intelligence machine : une plaisanterie?
Toutefois, c’est la différence entre comprendre l’esprit d‘un texte (l’intelligence) ou le prendre à la lettre, voire en trahir l’interprétation. Pour exemple, la première traduction par Marcel Aymonin du tchèque en français de la plaisanterie, de Milan Kundera, a été rejetée par l’auteur tant il la considérait comme une ré-écriture. Est-ce qu’une machine aurait des biais idéologiques dans la traduction ? Elle le pourrait, suivant son entraînement d’apprentissage. Surtout, elle n’aura aucune créativité pour rendre l’esprit d‘origine et ne fera qu’emprunter des tournures.
Certes, on peut analyser les sentiments d‘un texte suivant les expressions utilisées et donc les simuler mécaniquement. En revanche, en rendre les subtilités de raisonnement, les analogies et les nuances requiert … une intelligence plus humaine.
Ainsi l’ensemble des livres « écrits » à l’aide d’IA générative ne peuvent satisfaire que les amateurs de clichés communs. Que se passerait-il si un modèle d’IA générative préentraîné sur un large corpus multilangues traduisait Kundera ? On aurait probablement une nouvelle plaisanterie, pas l’esprit d’origine.
La réponse de ChatGPT à la différence entre 1kg de plumes et 1 g de plomb illustre ses difficultés logiques. Pourquoi la machine ne peut-elle résoudre une question aussi simple ? Parce qu’il faudrait qu’elle comprenne la différence entre les mesures. Elle n’a pas forcément cette connaissance. Dès lors, quelles connaissances une machine peut-elle détenir, apprendre, ou produire ?
De la représentation des connaissances du 18e à aujourd‘hui
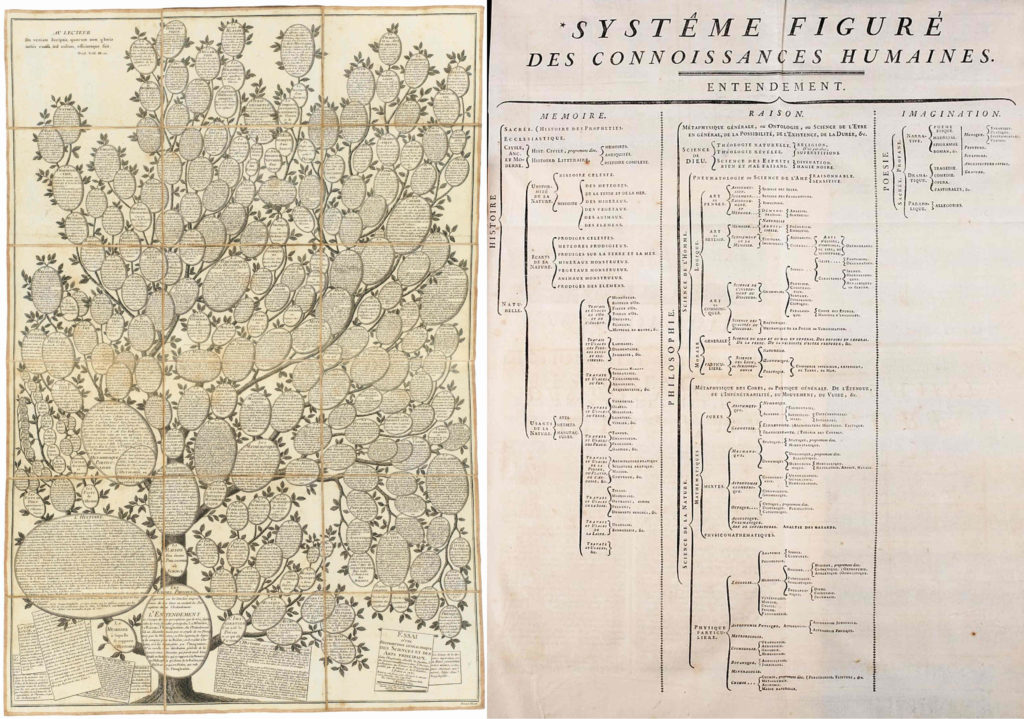
Représentation des connaissances par Diderot et d’Alembert
Pour tenter de répondre à la question précédente, explorons ce qui tourne autour du concept de connaissance. En particulier, dans un monde où on ne parle plus que de données, il est souvent utile de rappeler le processus qui les exploite pour arriver à la compréhension des caractéristiques d’une situation afin de pouvoir prendre des décisions et exécuter des actions. Toutefois, pour que ce processus ait lieu et construire de nouvelles connaissances, il faut déjà pouvoir représenter les existantes.
En 1752, l’ambition de Diderot et d’Alembert de représenter l’ensemble des savoirs humains les conduit à une taxonomie des connaissances humaines. Laquelle sera en 1780 figurée à l’aide d’un arbre, similaire à un cactus… Cette répartition hiérarchique classifie les concepts de connaissances entre trois branches principales : mémoire, raison et imagination.
Cette classification conduit à plusieurs pistes de réflexion sur la fabrique des « connaissances » d’une machine. D’une part, parce que nous avons évolué dans le champ des connaissances humaines ainsi que dans celui de leur représentation, d’autre part, parce que nous devons redéfinir le champ de l’ingénierie des connaissances pour la construction de systèmes dotés d’une certaine forme de savoir. D’ailleurs, c’est leur capacité à exploiter ce savoir à la demande, qui peut-être plus ou moins qualifiée d’intelligence. Les notions de raison et d’imagination chez une machine seront forcément limitées.
Avant de définir tous les concepts gravitant autour de l’ingénierie des connaissances, il est facile de souligner un truisme. La représentation des connaissances aujourd’hui n’est plus celle du 18e. En particulier, la notion de Knowledge graph représente la révolution copernicienne de la représentation des connaissances opérée au 21e siècle.
Des données liées au Knowledge Graph
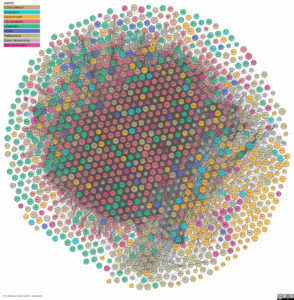
Image du Linked Open Data Cloud, 3 novembre 2022
Au 21e siècle, une encyclopédie de toute la connaissance serait une démarche pharaonique à coordonner par réseaux d’expertises ! Pour laquelle il faudrait d’abord déterminer des concepts de classification les plus communément partagés. Puis de constituer des modules thématiques liés entre eux par des noyaux de terminologies communes. Modularisation nécessaire du fait de la spécialisation et de l’évolution rapide de différents domaines de connaissance.
En outre, le Web a conduit à une autre logique d’exploration des connaissances que celle de la taxonomie de Diderot. D’abord guidée par des liens entre pages, cette exploration est désormais guidée par des liens entre objets, ou ensembles d’objets, tous nœuds de réseaux sémantiques interreliés. C’est la notion de Web des données liées (LOD = Linked Open Data).
En 2012, Google a annoncé son knowledge Graph, suivant le mouvement du LOD, et d’autres ont suivi. L’idée étant d’exprimer les données qui qualifient les contenus du Web et leurs dépendances de sens, pour naviguer dans ces liens et produire de la connaissance à l’issue de cette exploration. Chaque nœud d’un graphe peut être typé et sujet ou objet d’une relation orientée avec un autre. Le type ici est un type de concept (par exemple : voiture, personne, lieu, organisation, etc.). Cela nous conduit à de multiples liens, dans de multiples directions.
Des modèles spécifient la terminologie et les propriétés des concepts et des liens utilisés pour qualifier les objets d’un graphe. Les graphes obtenus contiennent à la fois des données et des modèles. Ils deviennent une source de connaissances pour la machine sous plusieurs conditions. La première est de pouvoir décrire formellement les modèles et les objets avec un langage lisible pour cette dernière. Ensuite, les définitions et les critères d’un « Knowledge Graph » varient suivant les acteurs et les objectifs. On peut expliquer pourquoi.
La notion de raisonnements, d’ontologies et de knowledge Base

Les variations de définitions se cristallisent autour de deux aspects de l’ingénierie des connaissances. Le premier aspect est la représentation des connaissances. Le second, celui de la production de connaissance par la machine. Par production on entend ici la capacité de la machine à produire des raisonnements qui conduisent à des conclusions.
En effet, si on veut donner une forme d’intelligence à la machine, il serait utile qu’elle puisse raisonner. Or il y a plusieurs manières de raisonner suivant que l’on fasse du raisonnement déductif, inductif, ou par analogie.
Le raisonnement déductif est celui qui se base sur des assertions logiques fournies en propositions d’entrée, pour en déduire une conclusion fondée sur des règles logiques d’inférence. Si on utilise des ontologies formelles pour représenter un domaine de connaissance, avec un consensus d’experts, on a un modèle que peut utiliser la machine pour établir des raisonnements déductifs.
En couplant des données factuelles se référant à ce modèle, en utilisant les formats standard du Web sémantique, RDF et OWL, on peut créer des bases de connaissances avec une structure de graphe, plus flexibles que des bases de données, facilement extensibles, qui permettent de plus des raisonnements déductifs. Un des avantages non des moindres de l’approche, c’est de pouvoir expliquer logiquement le raisonnement. Un préalable nécessaire, si on veut utiliser la connaissance pour prendre des décisions.
A contrario, le raisonnement inductif part d’observations répétées pour en déduire une généralisation théorique. Plus les observations (les données) sont nombreuses, plus la probabilité de véracité des déductions augmente. Dans ce cas de figure, on va plus s’intéresser à labéliser les données avec un vocabulaire contrôlé pour étiqueter des contenus, pour de l’indexation, par exemple. Ce vocabulaire sera un schéma plus qu’un modèle et restera nettement moins expressif et moins formel qu’une ontologie.
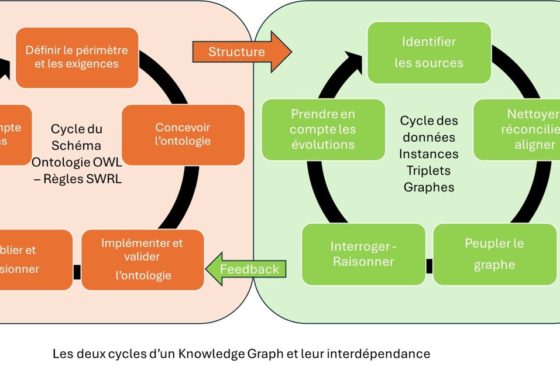
Les Knowledge Graphs selon les types de raisonnements machines
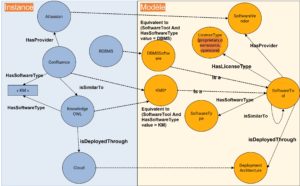
Example de Knowledge Graph avec instances et modèle
La définition donnée aux Knowledge Graphs varie suivant les préférences de raisonnement, voire les techniques utilisées. Dans le cas où on privilégie le premier type de raisonnement, il s’agit d’une approche d’IA symbolique. Appelée également « Knowledge Representation and Reasonning », l’accent porte sur la rigueur de la description et des règles logiques. Un moteur d’inférence est utilisé pour déduire de nouveaux faits. Le Knowledge Graph ici est une base de connaissance constituée d’une ontologie (le modèle sémantique) et d’individus (les données).
Dans la lignée des systèmes experts, cette approche a bénéficié d’un regain d’intérêt grâce aux standards du Web sémantique. OWL couplé avec SPARQL permettent de créer une architecture d’intégration par les données au-dessus d’applications et de sources hétérogènes. On peut ainsi viser à une interopérabilité sémantique. Reste pour l’obtenir à réutiliser des ontologies existantes et concevoir des ontologies cohérentes, extensibles, spécifiées explicitement et correctement.
Le processus est complexe. Car il nécessite, en plus de respecter la logique mathématique souvent oubliée dans les modélisations d‘applications, un consensus humain. De plus, si on veut pouvoir relier plusieurs graphes, il faut prévoir d’avoir à traiter des incohérences. Néanmoins, cette approche conduit à l’explicabilité des conclusions d’une IA. Elle reste à privilégier quand on ne traite pas de grands volumes de données.
Car pour la seconde approche, il en faut, ainsi que des techniques d’apprentissage machine. On parle alors d’abord de graphes de données interreliées, enrichies avec du sens, sur lesquelles raisonner. Le Knowledge Graph sert à calculer des proximités et des similarités en fonction des distances entre nœuds et on utilise aussi des techniques de vectorisation de mots (Word Embedding) sur des graphes complets (Knowledge Graph Embedding). Le problème, c’est qu’on perd et le sens et le mécanisme de fabrication de connaissances.
Alors, quelle intelligence donner à la machine?
.jpg)
Ce n’est pas parce qu’on n’a jamais vu de cygne noir qu’il n’en existe pas, ou plutôt, ce n’est pas parce que la majorité des capitales ont un aéroport que Vaduz en a un. Le raisonnement par induction ne démontre pas les conclusions, il les suppose par probabilité. Quant aux algorithmes de machine learning, ils peuvent faire des regroupements et des raisonnements par proximité. Or une proximité de concepts extraite par apprentissage profond dans une masse de données, ce n’est pas forcément une vérité démontrable, pas plus que cela ne certifie la possibilité d’analogie.
La machine n’a pas l’intelligence de raisonner par analogie, même si elle en donne l’impression. Avec certains types d’algorithmes, elle peut établir des sortes de proximité vectorielle. Toutefois, si elle rapproche des termes, ce ne sont pas de vrais rapports de proportionnalité. C’est pourquoi elle donnera l’illusion de faire des associations d’idées. En réalité elle n’a pas l’intelligence des correspondances. L’exemple entre 1kg de plumes et 1 g de plomb l’illustre, sans pousser sur des raisonnements analogiques complexes. La façon de calquer une structure de concepts sur une autre n’intègre pas la compréhension de la pertinence de l’analogie.
Quant à lui donner des capacités de raisonnements déductifs, encore faut-il que toutes les prémisses qu’on lui fournit soient vraies. Si on définit des choses fausses comme axiomes de départ, la véracité des conclusions s’en ressent forcément. La machine n’a pas d’intelligence critique vis-à-vis des axiomes qu’on lui spécifie.
En réalité, l’intelligence de la machine dépend des mécanismes (concepts, méthodes, techniques, processus) d’ingénierie des connaissances qui lui sont appliqués. On a donc tout intérêt à concevoir les capacités de cette machine en fonction d‘objectifs pour espérer raisonnablement les atteindre.
Knowledge Graph et ingénierie des connaissances
Alexa Steinbrück / Better Images of AI / Explainable AI / Licenced by CC-BY 4.0
Nous avons à peine abordé dans les paragraphes précédents la représentation et la production de connaissances par la machine. Alors qu’il s’agit d’une petite partie d’un domaine bien plus vaste, celui de l’ingénierie des connaissances. Ce dernier inclut l’ensemble des domaines suivants : Knowledge Acquisition, knowledge Discovery, Knowledge Transfer, Knowledge Validation, Knowledge Evolution, Knowledge Engineering Process.
Chacun de ces concepts a des liens avec les autres. Tous conduisent, pour plus d’efficacité, à mixer des techniques de représentation des connaissances et de raisonnement (KRR) à de l’apprentissage machine (Machine Learning) et du traitement automatique du langage (NLP). Tous nécessitent une démarche humaine raisonnée.
Pour exemple, dans l’acquisition de la connaissance par une machine, on rencontre le problème de l’élicitation de l’expertise humaine. Un mot bien savant pour expliquer une réalité : un grand nombre de connaissances, liées à un métier, par exemple, sont dites tacites. Elles sont dans l’esprit des personnes et ne sont pas formalisées de manière à être partageables, ou réutilisables. L’action de les représenter dans un langage commun, compréhensible par la machine et les humains les rend explicites et transférables.
Il faut donc commencer, avant de pouvoir acquérir des connaissances, par construire ce langage commun. Néanmoins cette action rencontre plusieurs freins, au-delà d’ailleurs de la seule appréhension à être dépossédé d’un savoir-faire. Ce n’est pas tant celui de disposer de personnes qui maîtrisent la formalisation en logiques de description des expertises. Ces compétences existent chez des ingénieurs ontologues. Les freins rencontrés sont, en particulier, d’obtenir un consensus d’experts sur le sens et les caractéristiques des concepts du domaine de connaissance qu’on veut représenter, et le temps nécessaire à établir ce consensus. Lequel ne peut exister si on ne clarifie pas dès le début le contexte de cette explicitation. Pourquoi faire ? Pour qui ?
La question de l’usage pour les Knowledge Graphs d’Entreprise (EKG)

Quelques exemples d’netreprises utilisant les Knowledge Graphs
Le Knowledge Graph Ouvert (OKG) de Google répond à des questions générales de recherche d’informations. Il existe de nombreux Knowledge Graphs en entreprise, lesquels ne sont pas visibles du grand public, qui poursuivent bien d’autres objectifs.
En effet, la capacité à suivre les dépendances de sens entre données peut alimenter de nombreux usages. L’analyse des causes de dysfonctionnements, l’analyse de risques financiers, la détection d’un comportement suspect, l’interconnexion entre différents capteurs hétérogènes qui se comprennent sans intervention humaine, les recommandations, la maintenance préventive, la surveillance, la recherche d’expertise, la capacité à rapprocher des compétences avec des postes, l’automatisation de processus et de règles métiers…
La liste est longue, bien au-delà de ce qu’on voit habituellement, c’est-à-dire l’optimisation de recherches ou la capacité d’un robot conversationnel à répondre à des questions d’expertises, en langage naturel ou pas.
Dans tous les cas, il est indispensable de définir un objectif d’usage au Knowledge Graph. Si c’est vraiment une approche d’exploitation des connaissances qu’il doit supporter, alors à quelles questions doit-il « savoir » répondre. Là est le nœud de sa conception. Suivant les questions auxquelles on souhaite répondre, on saura quels concepts et quelles relations manipuler. Le langage à manipuler pour traiter de risques financiers et les concepts à décrire ne sont pas les mêmes que pour traiter des règles de configuration de produits ou pour de la recherche d’expertise.
La validation d’un Knowledge Graph est celle de l’usage. Si la base de connaissance obtenue répond de façon pertinente et juste aux questions pour lesquelles elle a été conçue, alors le graphe aura réalisé son objectif. La structure du graphe et les technologies utilisées découlent également de l’objectif ainsi que des sources disponibles pour nourrir la base de connaissance.
La gouvernance de l’intelligence machine

On peut vouloir accélérer le processus d’acquisition en extrayant des entités et des relations de sources textuelles. Des techniques de NLP, combinées à de l’apprentissage profond y contribuent. Reste qu’en cas de volume de données limité et de règles logiques spécifiques, le machine learning aura ses limites.
Dans tous les cas, on voit de plus en plus un mélange entre IA symbolique et Machine Learning. En particulier, le recours à la première dans la seconde pallie le problème d’explicabilité tandis que le recours à la seconde dans la première pallie les problématiques de traitement de grands volumes dans l’acquisition. Néanmoins l’important n’est pas tant les techniques employées, que les processus qui les orchestrent et comment ils sont gouvernés.
S’il ‘n’y a pas de réflexion d’ensemble dans une entreprise, les knowledge graph perdront de leur intérêt. Autrement dit, en fabriquant des connaissances en silos, on a des connaissances en silos, difficilement reliables et exploitables. Sauf à mettre en place un langage commun et une gouvernance ad-hoc, aussi bien aux frontières que globale, pour les fédérer. Au-delà des processus, il faut clarifier les objectifs de création de valeur en explicitant les exigences des parties prenantes, les ressources nécessaires et les risques.
Les techniques ne répondront pas aux questions suivantes. Qui utilisera, validera ou s’assurera de la maintenance et de l’enrichissement des connaissances de la machine ? Pourquoi faire ? De quelles connaissances disposons-nous et desquelles les employés ont besoin pour travailler ?
A aucun moment il ne faut que ce processus d’interrogation n’échappe au contrôle humain. Car, encore une fois, une machine n’a ni sentience, ni intelligence propre. Les techniques peuvent aider à réduire les efforts, accélérer le temps de construction, c’est cela l’intelligence machine.
Mais donner un sens équilibré au but poursuivi, cela devrait rester du ressort de l’intelligence humaine.
question à ChatGPT : quelle est la différence entre 1 Kg de plume et 1 g de plomb?
La différence entre 1 kilogramme de plumes et 1 gramme de plomb est que le plomb est beaucoup plus dense et plus lourd que les plumes. Un kilogramme de plumes pèse environ 1 gramme, alors qu'un kilogramme de plomb pèse environ 1000 fois plus.