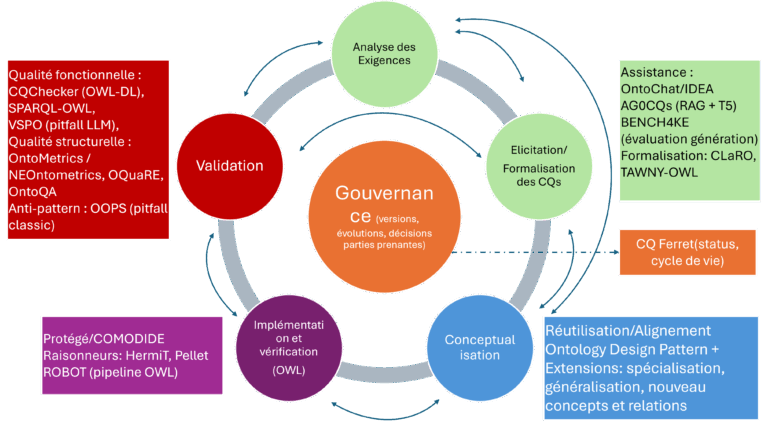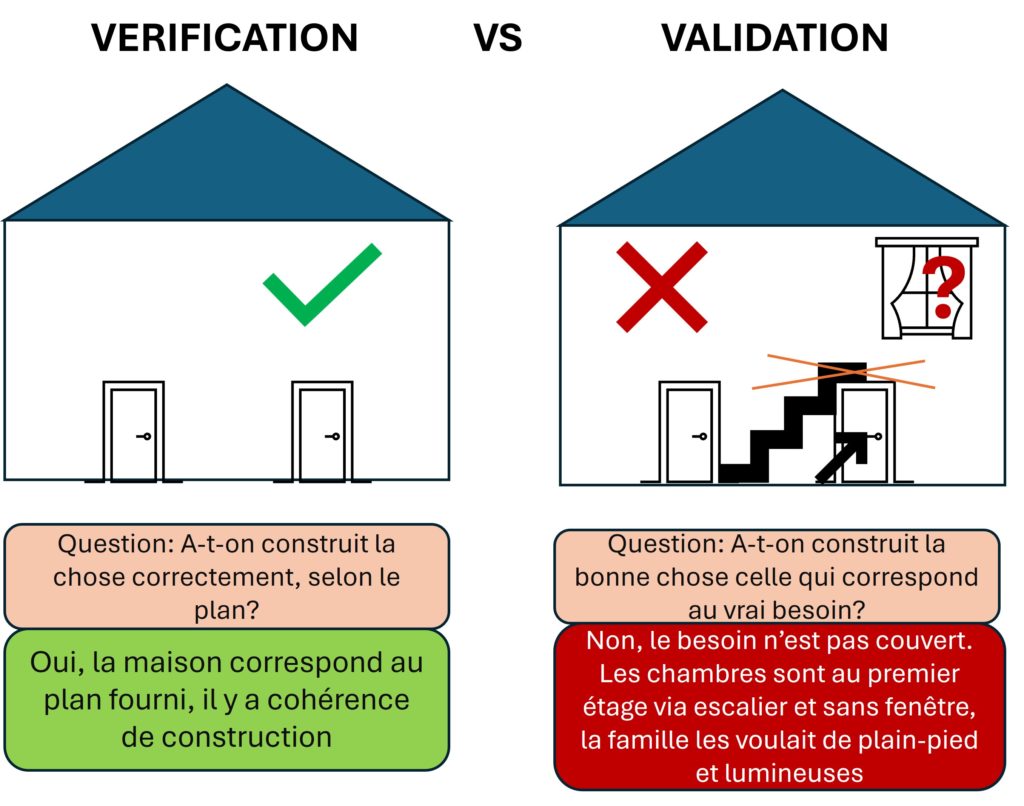
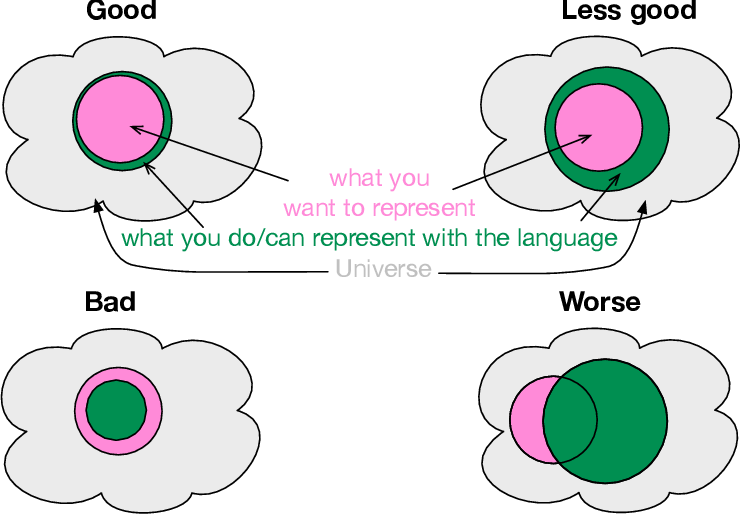

L’intelligence de l’ontologie est celle des liens que les experts savent faire entre objets déterminant de leur système de connaissance. Ces liens qui caractérisent les interactions entre concepts servent d’intelligence « artificielle » à la machine. Ils lui servent à reconnaitre qu’une chose est de telle nature, ou si elle est déclarée de telle nature, ce que cela implique. Valider l’adéquation sémantique revient à vérifier que l’ontologie produit, sur un corpus de référence, les mêmes réponses qu’un expert interrogé sur ce même corpus. Automatiser la validation à partir des questions de compétences une fois raffinées ne sera pas satisfaisant. Il faut avant de pouvoir faire cette validation :
- Valider si les questions de compétences ont bien été traduites en concepts et relations dans toutes leurs implications et qu’on a généré l’ensemble des sous-questions auxquelles elles doivent mener ;
- Valider qu’on dispose de ressources représentatives de la réalité couvrant toutes les questions et sous-questions auxquelles la base doit savoir répondre.
Ensuite, il faudrait faire une double validation, propre au test d’une ontologie OWL : à chaque question posée à un expert sur un pool de ressources, faire l’interrogation de la base et comparer les résultats.
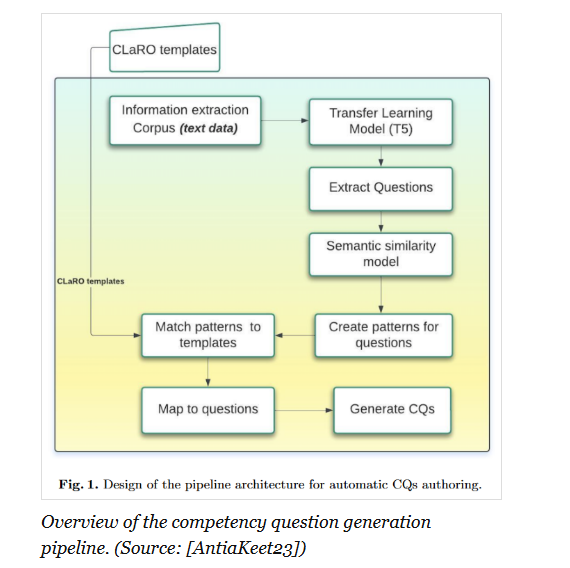
Récemment, de nouveaux outils sont apparus, nés la tentation d’utiliser les LLMs pour faciliter la construction des CQs. Des chercheurs dans le domaine académique (cf Keet) ont investigué cette piste avec l’idée de faire gagner du temps aussi bien aux experts des domaines métiers considérés qu’aux ingénieurs ontologues. Mais jusqu’à quel point l’approche CQs est-elle automatisable ? Il faut distinguer les outils dédiés à la construction des CQ (élicitation, formulation, raffinement) et ceux dédiés au test et à la validation (vérification que l’ontologie ou le knowledge graph répond effectivement aux CQ). En observant les essais réalisés sur le domaine, force est de constater que la volonté d’automatisation se heurte aux temps nécessaires de l’élicitation et de la compréhension.

L’idée de la plupart des systèmes de formulation de CQs avec des LLMs, c’est de passer par une étape intermédiaire plus proche de celles que connaissent les utilisateurs futurs du système de connaissance qu’on construit. En l’occurrence, il s’agit de les aider à formuler des user stories. Si ces dernières sont bien connues du paradigme de développement logiciel actuel pour collecter leurs exigences, elles ne servent ici que de « sas » d’entrée. Des outils comme les frameworks d’Ontology Requirements Engineering (ORE) OntoChat et IDEA (Infer, Design, creAte) proposent des templates de « user stories » qui seront ensuite traduites en CQs par les LLMs. Il y a toujours un humain dans la boucle : l’utilisateur.
Toutefois les retours d’expérience témoignent d’une certaine difficulté des utilisateurs avec ces framework, même avec des modèles, ils ont du mal à formuler efficacement leurs prompts. D’autres études proposent dès lors un accompagnement spécifique le « participatory prompting ». On peut se demander alors ce que le processus apporte de plus qu’un accompagnement direct à formuler les concepts de manière logique. On perd ici la spécificité de faire une spécification sans ambiguïté, en termes logiques, ce qui est la nature même des étapes d’élicitation des CQs. Il est donc nécessaire de repasser par des validateurs humains pour la logique.