
Home / Design, ingénierie des connaissances, KnowledgeGraph, ontologies / Les ontologies de fondation : pourquoi les ignorer peut finir par coûter cher
Les ontologies de fondation : pourquoi les ignorer peut finir par coûter cher
Des fondations que personne n'utilise… et qui manquent à tout le monde
Dans l’article précédent, j’expliquais l’importance d’une architecture multiniveau pour un réseau d’ontologies d’entreprise. Le niveau le plus haut étant celui des ontologies de fondation, TLO (Top Level Ontology), ou ULO (Upper Level Ontology).
Je soulignais également le peu d’usage chez les développeurs construisant des ontologies avec des TLO (moins de 30 %). Dans ce cas, pourquoi faire un billet de meilleures pratiques sur les TLOs si elles sont si peu utilisées ? Je vais y répondre en utilisant le terme même de fondations.
Il ne faut pas confondre utilité, rapidité et habitudes. À certains endroits, on peut construire une maison sans fondations rapidement avec de l’argile. Il se pourrait même qu’elle tienne un moment, sans ouragan, inondation ou autre événement. Mais jusqu’à quand ? Avoir un toit tout de suite, c’est bien. L’avoir à long terme, c’est mieux. Les fondations, c’est une question de maîtrise du risque.
Je suis convaincue que ce n’est pas le manque d’utilité des TLO qui en fait des mal-aimées, mais leur courbe d’apprentissage. D‘où la tentation de les écarter par facilité, dans un monde envahi par les LLMs et soumis à l’injonction de rapidité. Cette facilité révèle pourtant des lacunes très répandues sur ce que sont les ontologies formelles.
À vrai dire, le paradoxe aujourd’hui est que le terme ontologie est de plus en plus galvaudé au fur et à mesure où on commence à en percevoir le potentiel en même temps que les limites des LLMs.

Données liées ≠ connaissance : le malentendu qui fragilise l'IA
Car les ontologies sont au cœur de l’ingénierie des connaissances et du raisonnement machine. Sans elles, les graphes et les LLMs relient des informations par des similarités vectorielles mais pas par un raisonnement logique. On est dans le domaine des patrons statistiques, des corrélations, pas de la déduction.
Les « hallucinations » des LLMs sont structurelles. Avant l’engouement du grand public pour l’IA générative grâce à ChatGPT, je rappelais, me référant à Doug Lenat, que « savoir que x est relié à Y est très loin du fait de comprendre X et Y » (cf. article « Un monde rempli d’incohérences n’empêche pas de raisonner »). J’expliquais également dans l’article « Intelligence artificielle ou data science sans conscience » qu’une donnée ne vaut que par le sens à en tirer. Au-delà du sens commun, quel sens les modèles prédictifs construits sur des modèles statistiques fournissent-ils vraiment ? Cela dépend de la fiabilité, de la pertinence, de la qualité de leurs jeux de données, mais aussi de la qualité des liens entre données pour les déductions qu’ils permettent.
On a voulu faire du RAG avec des LLMs pour donner plus de connaissances contextuelles à la machine. Les limites d’une telle approche sont bien documentées : la similarité vectorielle ne permet pas de raisonnement complexe.
Le GraphRAG a donc succédé au RAG, en fournissant des graphes de données liées en entrée au lieu de texte. Oui, mais les données liées ne sont pas non plus forcément liées par des ontologies. On peut créer des métadonnées, mettre des étiquettes sur les choses pour les retrouver plus facilement. C’est le principe de schema.org : cela permet de dire qu’une entité web est de telle nature, décrire ses caractéristiques, ajouter quelques relations.
Pas de raisonnement autonome sans rigueur logique et compréhension métier
Mais rien de tout cela n’est de la description logique pour favoriser le raisonnement. Il ne suffit pas de lier des données à des métadonnées pour dire qu’on dispose d’une ontologie. Il ne suffit pas plus d’avoir un graphe de métadonnées pour avoir un graphe de connaissance.
Nous confondons trop souvent les données reliées par de simples schémas de métadonnées dans des graphes avec de véritables graphes de connaissances. Cette distinction n’est pas une simple querelle académique ; elle a d’ailleurs conduit à rebaptiser le « Web sémantique » en « Web des données liées », tant la dimension sémantique profonde peinait à s’y imposer. Sans doute était-il stratégique, pour avancer rapidement, de ne pas s’appesantir sur des structures logiques rigoureuses.
Cependant, alors que des entreprises se lancent aujourd’hui dans la vente ou dans l’implémentation d’agents dits « autonomes » (soit capables de décisions étayées), il est temps de clarifier le paysage. Pour atteindre un véritable raisonnement, une couche de description logique du sens est indispensable. Sans elle, nous risquons de bâtir sur des fondations fragiles, or force est de constater qu’elles font souvent défaut.
Modéliser un véhicule : quand la précision ontologique change tout
Pour rendre cela concret, prenons un exemple que tout le monde croit connaître : une voiture. Décrire le sens des choses ne se limite pas à affirmer qu’une voiture est un « véhicule qui roule ». Lorsqu’on définit un véhicule, il convient de préciser s’il s’agit d’un engin terrestre, aérien ou maritime, et d’expliciter les implications de ces distinctions. Un véhicule n’est pas un concept abstrait ; c’est un objet physique possédant une continuité temporelle, des qualités intrinsèques et occupant un espace spatio-temporel.
Dès lors, que signifie « rouler » ? S’agit-il d’une trajectoire… ou d’une action ? Peut-on modéliser la conduite comme un processus auquel le véhicule et le conducteur participent, ou bien est-ce le déplacement lui-même qui constitue le processus, lié à une localisation temporelle précise ? Pour répondre à ces questions, les ontologies de fondation (comme DOLCE, BFO ou UFO) sont essentielles. Elles permettent de faire des choix de modélisation rigoureux. Par exemple :
- Dans BFO [1], on distinguerait clairement le véhicule comme un Continuant (un objet matériel) dont le mouvement est un Occurrent (un processus).
- Dans DOLCE [2], on pourrait analyser le véhicule comme un Endurant participant à un Perdurant (le voyage), tout en spécifiant ses propriétés qualitatives et quantitatives.
- Dans UFO [3], le véhicule est classé comme une Substance (Material Object). Le mouvement est un Event auquel le véhicule participe via un Relator de Participation. Le véhicule endosse le Rôle de « transporteur en déplacement » dans une Situation qui fixe le cadre spatio-temporel. La vitesse est une Qualité inhérente à cette Participation, et non à l’objet statique.
Quand les objets changent de rôle : modéliser la dynamique des situations
De même, on peut envisager le véhicule comme jouant un rôle spécifique dans un scénario donné. Si l’on traite de véhicules équipés de capteurs dans un graphe de connaissances, on souhaite souvent les localiser en temps réel (coordonnées, altitude, zone maritime) et associer leur statut à des intervalles de temps et des activités (déploiement, mission, durée d’une tâche).
Les ontologies de fondation aident à formaliser ces relations complexes. Par exemple, DOLCE+DnS (DOLCE + Descriptions and Situations) permet de modéliser explicitement les situations et les rôles, distinguant l’objet physique de la fonction qu’il remplit dans un contexte donné.
De ces choix de modélisation découlent des déductions sur des faits, grâce à des raisonneurs standards capables de gérer efficacement les inférences de rôles, de phases et de contraintes. Cela est particulièrement utile dans des environnements dynamiques où les entités changent de fonction (véhicules multimodaux, personnel affecté à différents postes).
Intégrer les TLO : maintenant, plus tard, ou jamais ?
Si les ontologies contiennent des axiomes et des règles logiques, c’est précisément pour doter les machines de capacités de raisonnement automatique. L’objectif n’est pas seulement de classifier des documents avec des étiquettes de métadonnées ou de rechercher des synonymes et des hiérarchies de concepts. Que l’on utilise OWL, SWRL ou d’autres langages, l’obtention de résultats fiables nécessite de passer par la logique descriptive et de comprendre les implications des assertions définies. À cet égard, les ontologies de fondation fournissent des cadres de référence indispensables, tant pour les débutants que pour les praticiens expérimentés.
Ces ontologies sont le fruit d’années de réflexion, permettant de définir des concepts cohérents en instanciant des classes générales qu’elles établissent déjà, ou en les spécialisant et en les enrichissant. Avec une ontologie de fondation, redéfinir des notions fondamentales comme rôle, processus, entité matérielle, objet, qualité ou quantité devient superflu, car elles sont conçues pour servir de socle, reliant les concepts spécifiques que l’on souhaite définir à un ensemble plus général et universel.
On peut choisir d’intégrer ces ontologies dès le début de la construction d’un système ou en phase de refonte. Mais les ignorer, c’est prendre le risque de ne pas réfléchir à long terme aux fondations logiques de ses modèles, compromettant ainsi leur qualité, leur réutilisabilité et leur potentiel d’inférence pour les raisonneurs.
Le verrouillage conceptuel : un autre problème d’héritage dans les SI
Il y a toutefois bien un choix stratégique à faire sur le moment de les prendre en compte.
L’alignement tardif présente un danger majeur : l’effet de verrouillage conceptuel. Une fois que les concepts sont définis sans cadre ULO, ils tendent à refléter la sémantique implicite des experts métier plutôt que des catégories ontologiques rigoureuses. Par exemple :
- Confondre un Rôle (ex : « transport de troupes ») avec un Objet (ex : « véhicule blindé »), rendant impossible la réaffectation dynamique d’un même véhicule à plusieurs rôles successifs.
- Traiter un Processus (ex : « vol de transit ») comme un Objet. Une erreur car les variations de vitesse sont des changements de qualité qui se produisent pendant le processus, pas des propriétés d’un objet statique.
- Confondre une Process Boundary (l’instant sans épaisseur temporelle où un convoi atteint son point de rendez-vous) avec la Spatiotemporal Region qui définit où et quand cet instant peut se produire. L’une est un événement déclencheur, l’autre est un cadre.
- Confondre la position réelle d’un véhicule (qualité inhérente, non copiable) et le rapport de position transmis (représentation archivable, potentiellement erronée ou obsolète). Ce qui rend impossible toute détection d’anomalie de transmission.
Les erreurs de conception : la partie immergée de l'iceberg
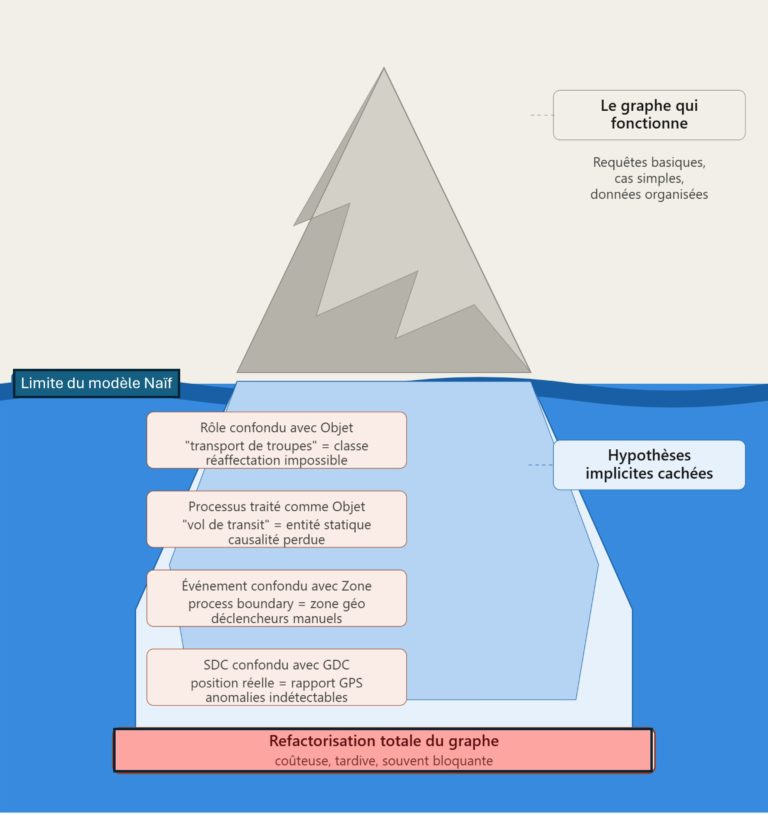
Ces erreurs ne rendent pas le système immédiatement inutilisable.
Elles le fragilisent là où la complexité opérationnelle réelle commence : raisonner sur la causalité, modéliser des règles de déclenchement automatique, tenir un historique de situation. Les corriger après coup demande souvent de refactoriser l’ensemble du graphe. Ce qui est toujours plus coûteux qu’avoir posé les bonnes fondations dès le départ.
Prendre en compte les ULOs au début, par contre, présente une courbe d’apprentissage élevée pour les experts du domaine, et ralentit la vitesse de prototypage par des débats sur la nature fondamentale des concepts, au risque que les experts ne soient plus concentrés sur leur domaine propre.
L'ontologue comme traducteur : un métier clé, encore invisible

Il existe toutefois une approche intermédiaire : qu’un ontologue agisse comme « traducteur » compétent entre le monde des experts et le cadre ULO. Cette approche repose sur l’expertise des ontologues, un métier à part entière, encore sous-représenté.
Cela implique certaines conditions de succès :
Trois piliers pour des agents autonomes qui tiennent dans le temps
Que l’on choisisse l’intégration précoce ou un alignement tardif piloté par un ontologue , s’appuyer sur une TLO permet de stabiliser trois piliers essentiels pour la durabilité des systèmes d’agents autonomes ou semi-autonomes.
- Maintenabilité : des ontologies et des Knowledge Graphs évolutifs
- Interopérabilité : entre systèmes hétérogènes
- Raisonnement : des capacités d’inférence optimisées
Nous avons rajouté une pièce du puzzle des bonnes pratiques des Knowledge Graphs avec les ontologies de fondation. Mais ceci est affaire de terminologie (TBOX) qui structure les métadonnées de la base de connaissance. Si on en vient aux assertions, c’est-à-dire aux individus qui vont peupler la base, d’autres questions sur l’architecture des fondations se posent. Le prochain article traitera de la qualité des ontologies et du rôle des raisonneurs, avant d’aborder dans le suivant les défis d’échelle que pose l’interrogation de gros volumes d’assertions.
Références
[1]BFO=Basic Formal Ontology. BFO est une ontologie de haut niveau (Upper Level Ontology) , concise, conçue pour faciliter la recherche, l'analyse et l'intégration d'informations dans les domaines scientifiques et autres. Elle ne contient pas de termes physiques, chimiques, biologiques ou autres relevant des domaines spécifiques des sciences. Initié dès 2001, la théorie derrière BFO a été développée par Barry Smith et Pierre Grenon. BFO est l’ontologie noyau de l’OBO Foundry( Open Biological and Biomedical Ontologies). Le répertoire suivant contient les artefacts BFO 2020 spécifiés dans ISO 21838-2 :2020 : https://github.com/bfo-ontology/BFO-2020
[2] DOLCE= Descriptive Ontology for Linguistic and Cognitive Engineering. Comme l’indiquent les auteurs de [4] DOLCE, en tant qu’ontologie de fondation «fournit des catégories générales et des relations qui peuvent être réutilisées dans différents scénarios d'application en les spécialisant aux domaines spécifiques à modéliser. ». Elle « est restée stable pendant vingt ans ». et est largement utilisée pour servir de médiation entre de nombreux domaines. « DOLCE s'inspire de considérations cognitives et linguistiques et vise à modéliser une vision du monde basée sur le sens commun, comme celle que les êtres humains exploitent dans la vie quotidienne dans des domaines aussi divers que les systèmes sociotechniques, la fabrication, les transactions financières et le patrimoine culturel. DOLCE énumère clairement les choix ontologiques sur lesquels elle repose, s'appuie sur des principes philosophiques, est richement formalisée et est construite selon des méthodologies ontologiques bien établies, i.e OntoClean ».
[3] UFO= Unified Foundational Ontology, moins répandue que les deux précédentes, a, selon [5] « été développée au cours des deux dernières décennies en mettant systématiquement en commun des théories de domaines tels que l'ontologie formelle en philosophie, les sciences cognitives, la linguistique et la logique philosophique. Elle comprend un certain nombre de micro-théories abordant des notions fondamentales de modélisation conceptuelle, y compris les types d'entités et les types de relations. »
[4] Borgo, S., Ferrario, R., Gangemi, A., Guarino, N., Masolo, C., Porello, D., Sanfilippo, E. M., & Vieu, L. (2023). DOLCE: A Descriptive Ontology for Linguistic and Cognitive Engineering. ArXiv. https://doi.org/10.3233/AO-210259
[5] Guizzardi, Giancarlo & Benevides, Alessander & Fonseca, Claudenir & Porello, Daniele & Almeida, João & Prince Sales, Tiago. (2022). UFO: Unified Foundational Ontology. Applied Ontology. 10.3233/AO-210256.