
Un monde rempli d’incohérences n’empêche pas de raisonner

Connaissances et raisonnements sont liés pour les humains, mais aussi pour les machines. Pour leur donner une forme d’intelligence, il faut relever l’enjeu de représentation des connaissances et de logique de raisonnement. C’est le domaine du «SRR : symbolic representation and Reasoning », un des deux paradigmes, avec le Machine Learning, de l’intelligence artificielle.
Certes, faire inférer des nouvelles informations à des machines dans un monde de réutilisation largement ouvert, pose des problèmes d’incohérences. Les évolutions des dernières années ont montré qu’ils n’étaient pas insolubles. Malheureusement, on en est resté plutôt à des systèmes d’Intelligences Artificielles très superficielles. Bien qu’elles sachent faire des corrélations, en liant X et Y, elles ne comprennent pas grand-chose à ce qu’elles lient. On peut faire mieux et apprendre aux machines à raisonner dans un environnement incohérent. Les outils et méthodes sont là. Alors quel est le principal frein ? Fournir les efforts humains de modélisations ontologiques qui permettront d’exploiter le raisonnement de manière optimal. Cela demande des compétences.
Connaissances et raisonnements pour les machines

Image du film hôtel du Nord (1938) avec Arletty
Les ontologies informatiques lient par leur approche de représentation formelle, connaissances et raisonnement. Elles servent à rendre les machines capables de déduction sur des bases de connaissances. Grâce à des programmes appelés raisonneurs. Sous réserve d’avoir spécifié un domaine de connaissance en langage formel . Ce qui a été défini dans l’article : Ontologie! Ontologie! Est-ce que j’ai une gueule d’ontologie?
Les technologies du Web sémantique, ont ouvert la possibilité à plus d’interopérabilité entre systèmes à l’échelle mondiale. En particulier par la voie de la représentation formelle des connaissances à l’aide de standards, dont OWL (Ontology Web Language). En liant les informations par des données que les machines peuvent comprendre et traiter grâce à des vocabulaires contrôlés. Mais pour atteindre le plein potentiel de l’approche, il faut pouvoir réutiliser largement les vocabulaires. Or plus il y aura de réutilisations, plus il y aura de contradictions, et de difficultés de résolution pour raisonner sur les informations.
Ainsi qu’indiqué dans le guide du W3C de 2004, « le langage OWL doit permettre de réunir des informations en provenance de sources réparties. On y parvient en partie en permettant aux ontologies d’être reliées. Y compris en important explicitement des informations d’autres ontologies. En outre, le langage OWL présuppose un monde ouvert. C’est-à-dire que les descriptions de ressources ne se réduisent pas à un seul fichier ou à une seule influence. Bien que la définition originale d’une classe C1 puisse se trouver dans l’ontologie O1, on peut l’étendre dans d’autres ontologies. Les conséquences de ces propositions supplémentaires sur C1 sont monotoniques. Les nouvelles informations ne peuvent pas désavouer les précédentes. Elles peuvent être contradictoires mais les faits et les inférences peuvent seulement s’ajouter, et jamais s’annuler. Le concepteur d’une ontologie doit tenir compte de la possibilité de telles contradictions. »
Concevoir les contradictions
]")
D’une part, cela signifie que toute modélisation en OWL des concepts d’un domaine peut être réutilisée dans une autre. Cette réutilisation est même un principe fondateur du Web sémantique. D’autre part, les axiomes, relations et règles de la seconde ontologie peuvent entrer en contradiction logique avec la première. Si c’est le cas, on pourrait avoir du mal à utiliser l’ensemble pour des raisonnements par des agents logiciels. Sauf à disposer de remédiations pour éviter des blocages en cas d’incohérence. Le guide du W3C ajoute « les outils devraient pouvoir aider à détecter ces cas de contradictions entre ontologies. ».
Si on raisonne complètement dans un monde ouvert, au niveau global, on arrivera forcément à des incohérences. Si dans un vocabulaire on détermine deux concepts comme disjoints, et dans un autre, l’un des concepts comme spécialisation du premier, on a une incohérence. Or si chacun peut importer des ontologies publiques pour en faire des généralisations ou des spécialisations de son côté, de telles choses peuvent arriver. Surtout que dans la pratique, les ontologies de différents systèmes sont développées indépendamment les unes des autres, par des communautés différentes, et pour des buts différents. Par conséquent, de réutilisation en réutilisation et d’inférences en inférences, on peut se retrouver en pleine incohérence.
Voir ici une petite démonstration logique de ce problème d’incohérence avec «The Organization Ontology», recommandation du W3C en 2014.
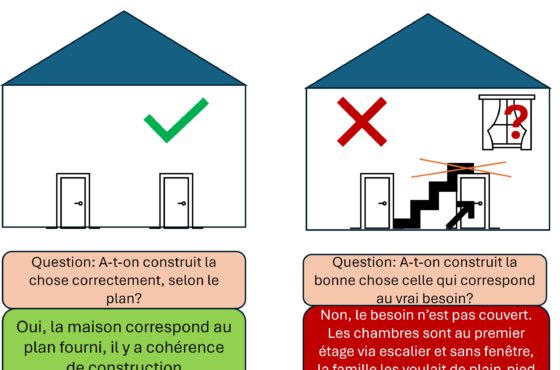
En théorie, les ontologies sont la clé pour une plus grande interopérabilité des systèmes distribués. Parce qu’elles permettent l’interopérabilité sémantique entre source de données. En pratique, il existe des problèmes d’interopérabilité sémantique entre ontologies.En théorie, il n’y a pas de différence entre la théorie et la pratique. En pratique, si.
Unknown.
Complexité apparente n’est pas problème insoluble !
On comprend dès lors toute la problématique d’intégration des ontologies entre elles, qui recouvre de nombreux domaines actifs du fait du large éventail d’applications. Alignement d’ontologies pour trouver des correspondances et pouvoir les relier, mais aussi évaluation et validation d’ontologies, fusion, extension, enrichissement … Tout un domaine d’ingénierie ontologique dont la complexité apparente semble freiner le développement de systèmes d’inférence à base de connaissances.
Est-ce à dire que le principe de faire inférer des déductions à des machines dans un monde de réutilisation largement ouvert, pose des problèmes insolubles ?

Si cela génère effectivement une multitude de problèmes, ils ne sont pas insolubles. Les solutions existent dans les outils, en particulier dans les raisonneurs, les puissances de calcul sont là. C’est ce que met en avant Doug Lenat dans son article paru dans Forbes en février 2019. « Not Good As Gold: Today’s AI’s Are Dangerously Lacking In AU (Artificial Understanding) ». Il y aborde la différence entre «Machine Learning » et systèmes d’inférence à base de connaissances formalisées (ou SRR : symbolic Representation and Reasoning). Et pourquoi il estime que le second, sous-exploité, est plus prometteur et efficace que le premier, pourtant mieux considéré.
Professeur dans les années 70s de “Machine Learning” à Stanford, Doug Lenat connait bien ce sujet. Selon lui, « les formes actuelles d’IA peuvent reconnaître des motifs récurrents sous-jacents qui relient des données, mais en réalité elles n’y comprennent pas grand-chose. […] Il y a un autre type de technologies d’IA. Qui impliquent de représenter des parties de la connaissance de façon explicite, symbolique, de manière à représenter un modèle du monde (ou d’une partie du monde) et ensuite de réaliser des inférences logiques sur des faits, étapes par étapes, à partir de ce modèle pour arriver à de nouvelles conclusions qui seront la base d’un raisonnement logique encore plus approfondi.
“savoir que x est relié à y est très loin du fait de comprendre x et y”.
On peut l’envisager comme les démonstrations de déduction éblouissantes du personnage de Sherlock Holmes. […] Le ML (Machine Learning) est une forme d’inférence statistique : des réseaux neuronaux multi-couches entraînés par des gros jeux de données. Par contraste, ce que j’évoque ici est l’inférence à partir de la connaissance. La différence est très semblable à ce qui sépare principe de corrélation et principe de causalité ».
Si un système de ML nous indique qu’il y a corrélation entre des faits, cela ne le rend pas intelligent pour autant. La corrélation n’est pas l’intelligence au sens où ce n’est pas la compréhension de son environnement pour s’y adapter. La machine ne comprend rien, elle indique avoir vu un lien entre x et y. Typiquement, un officier de police pourra avoir de fortes présomptions de culpabilité sur l’apparence et le langage d’une personne, basées sur des statistiques. Mais en aucun cas cela ne veut dire que l’officier aura investigué sur des propositions vraies pour déduire en conclusion l’innocence ou la culpabilité de la personne.
Doug Lenat ajoute que ces deux paradigmes d’IA, entre corrélation et causalité, existent depuis les années 70s. « Chaque approche a ensuite rencontré d’énormes obstacles bloquant sa progression pendant plusieurs décennies. Cependant, au cours des 50 dernières années, plusieurs choses ont changé qui permettent de revoir et d’exploiter ces deux approches de manière efficace et rentable ».
De plus, si l’approche à base d’inférences sur des connaissances rencontrait encore plus d’obstacles que sa rivale, elle les a tout autant franchis.
Des avancées considérables mais une exploitation superficielle
Le monde réel est plein d’incohérences! Comment pouvons-nous concilier cela avec la nécessité d’une cohérence logique des bases de connaissances si nous devons utiliser une quelconque logique pour déduire un nouveau contenu? Pour remédier à ce problème d’incohérence omniprésente, nous avons dû remplacer l’exigence de cohérence globale des bases de connaissances avec la notion de cohérence locale.
Doug Lenat.
Doug Lenat détaille en particulier les avancées considérables en matière de réutilisabilité d’ontologies, d’efficacité des raisonneurs, de traitement des incohérences omniprésentes, d’intégration des Big data dans la base de connaissances (usage de sources hétérogènes sans avoir à tout charger en centralisé grâce à l’interrogation à distance des sources tierces pertinentes après alignement ontologique), et également en termes de présentation aux utilisateurs du système. Ces derniers doivent pouvoir comprendre les déductions du système, pour lui faire confiance, donc attendent des explications en langage compréhensible.
D’autre part, les utilisateurs ne doivent pas avoir à connaître les règles logiques pour l’interrogation et la navigation dans la base de connaissances. Là encore, une remédiation simple à un problème complexe peut répondre avec de bonnes performances : la génération de langage naturel. Assez facile à réaliser en partant d’algorithmes de composition récursive qui exploitent les assertions logiques. Cela marche particulièrement bien … en Anglais.
Pour finir Doug Lenat note que les systèmes d’IA d’orientation SR&R (Semantic Representation and Reasonning) n’exploitent pas assez la représentation des connaissances. Chercheurs et développeurs d’applications n’utilisent qu’un « vernis de connaissance ».
« Certains des meilleurs systèmes d’intelligence artificielle actuels ont et utilisent effectivement des sortes de représentations symboliques et des moteurs de raisonnement, mais les représentations de la connaissance qu’ils utilisent (triple store, ontologies RDF / OWL, graphes de connaissance, etc.) sont beaucoup trop superficielles. ».
Cette superficialité s’entend au sens de comprendre les questions posées et y répondre par des déductions avancées. Les possibilités d’inférence sont très peu utilisées, en théorie, pour des raisons d’efficience des raisonneurs.
Le sens de l’effort de modélisation ontologique.
Clairement, pour sortir de cette superficialité, Doug lenat préconise de pousser plus loin les efforts de modélisations ontologiques, impliquant « la rédaction des déclarations formelles dans ce langage qui capture la pragmatique du monde réel (ou des mondes fictionnels tels que l’univers Marvel si on veut raisonner dessus) et traiter sérieusement les argumentations pour et contre [des déductions] ».

Représenter connaissances et raisonnements logique pour une machine n’est pas intuitif. Cela exige de la rigueur dans la modélisation. Une rigueur indispensable car, pour poursuivre le point de vue de Doug Lenat, disposer de base des connaissances de qualité, c’est-à-dire qui représentent correctement les connaissances du domaine, est un des facteurs déterminants pour un système d’aide à la décision efficace. Cela demande encore des efforts humains pour obtenir une modélisation des connaissances qui permette d’exploiter le raisonnement de manière optimale. Aucun outil ne remplace aujourd’hui l’intelligence humaine pour cela. Même si certains outils peuvent aider les experts à formaliser et partager des expertises, réduire et mieux diriger l’effort de conception. Voir aussi cet article de Kurt Cagle paru en mars 2019 dans le magazine Forbes : « Taxonomies, Ontologies And Machine Learning: The Future Of Knowledge Management« .
En d’autres termes, nous sommes capables aujourd’hui de réaliser des systèmes réellement dotés d’un certain niveau de compréhension logique. Il y a un chemin connu, des méthodes et des outils pour cela. Mais ne vous attendez pas à ce que soit un algorithme intelligent qui apprenne et comprenne par lui-même. Ce n’est pas magique. Il faut derrière des bons modèles de connaissance et des humains, pour une amélioration incrémentale des modèles.
Un métier « d’Homme-orchestre »: les ingénieurs ontologistes

On a besoin de compétences particulières, en d’autres termes, « d’ingénieurs ontologistes ». Un métier qui n’est pas dans tous les référentiels et que certains peinent à comprendre. Pour preuve, cette tentative d’explication en 2017 par un « ontologiste » pratiquant dans la data science et se plaignant de ne pas trouver de définition. Désormais, deux ans après, on trouve « ontologist » dans les recherches Google. Cependant, les descriptions d’offres d’emplois demandent des profils aux compétences très variées. Car c’est un métier qui est à la croisée des chemins, entre la compréhension du langage, la modélisation formelle du sens des choses, la gestion et l’ingénierie des connaissances, et la compréhension des usages des données et des systèmes informatiques. Mais c’est également un métier avec des méthodes et des outils.
En effet, l’ingénierie ontologique a beaucoup progressé ces dernières années pour justement augmenter la qualité des modèles. Définition de patrons de conception (Ontology Design pattern), principe de conception de réseaux d’ontologies fortement indépendantes et modulaires, mais liées par des ontologies noyaux et génériques (upper-level), pour plus d’efficacité et de réutilisabilité, portails d’ontologies et vocabulaires de métadonnées pour décrire et rechercher les ontologies (avec les notions de traçabilité, de qualité et de cycle de vie), meilleures pratiques de conception, outils de plus en plus industriels avec des interfaces plus conviviales…
Si les méthodes de l’Ingénierie Ontologique n’ont peut-être pas encore atteint la maturité des méthodes du Génie Logiciel, elles en prennent le chemin. Lequel nous mène vers plus d’interopérabilité des systèmes distribués, car ils pourront logiquement se comprendre. Comme nous essayons de le faire tous dans un monde ouvert, où les incohérences existeront toujours.
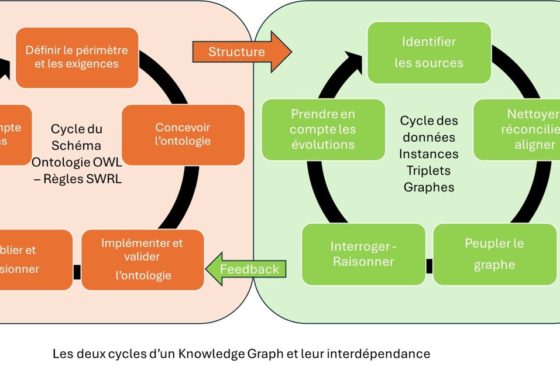

[…] Un avantage des ontologies OWL réside aussi dans la mise à disposition d’outils capables de raisonner sur elles. Mais ainsi qu’indiqué par le W3C dans son premier guide OWL, « construire un système de raisonnement solide et utile n’est pas une affaire simple ». Il y a des problématiques de décidabilité (terminer les calculs dans un intervalle de temps fini) des systèmes de raisonnement et aussi de grosses contradictions entre ontologies, du fait de réutilisation pas toujours cohérentes. Heureusement, il y a eu beaucoup d’évolutions depuis 2004, et les systèmes d’inférence ont eux aussi connu le renouveau de l’Intelligence Artificielle. Ce sera d’ailleurs l’objet d’un prochain article (Un monde rempli d’incohérences n’empêche pas de raisonner). […]