Alien Arrival Credit photo : compte flickr Steve Crane, licence cc-By-NC-ND 2.0
ChatGPT utilise un modèle transformer : and so what ?
ChatGPT est un agent conversationnel (ChatBot) qui utilise un modèle transformer GPT-3.5 (Generative Pre-trained Transformer) pour comprendre et répondre à des questions d’utilisateurs. Il reprend les principes d’InstructGPT et utilise un apprentissage par renforcement avec un feedback humain (RLHF) pour améliorer ses réponses.
Soyons honnêtes : ces deux phrases n’apprennent rien à personne. Ceux qui travaillent dans le domaine le savent déjà. Quant aux autres, cela ne clarifie rien. Car le premier point d’interrogation demeure : qu’est-ce qu’un modèle Transformer ?
Quand on traite d’Intelligence Artificielle, on sépare souvent deux grands domaines : IA symbolique et apprentissage machine (Machine Learning). Le premier utilise des symboles pour représenter des informations et des connaissances. Le second utilise des algorithmes pour apprendre à partir de données à effectuer des tâches. En ce qui concerne ChatGPT, ce sont des tâches de traitement automatique du langage (TAL ou Natural Language Processing(NLP)).
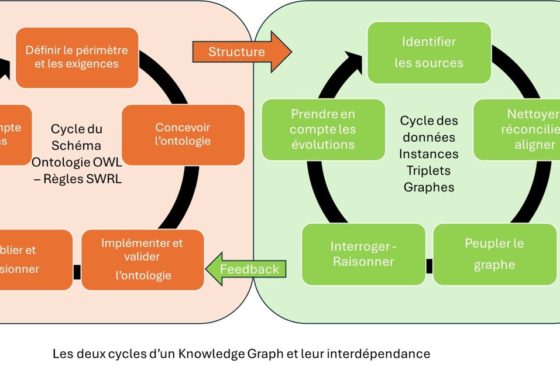
On a tendance à renvoyer l’IA symbolique aux anciens systèmes experts pour simplifier. En fait, il s’agit de représentation formelle des connaissances et de règles logiques de raisonnement. Ce sont des humains qui construisent et explicitent ces représentations et ces règles, dans des ontologies, par exemple. Ces dernières étant exprimées en un langage de logique de description tel OWL, les machines peuvent alors interpréter sans ambiguïté les symboles. Les graphes de connaissances les utilisent pour lier et qualifier les informations qu’ils contiennent. On est dans le domaine du KRR (Knowledge Representation and Reasoning). Si l’effort de formalisation des connaissances est non négligeable, il aboutit à un système avec lequel on peut expliciter le raisonnement conduisant à une décision.
En revanche, si on veut analyser des images, des vidéos, des enregistrements vocaux, les classifier automatiquement ou être capables d’identifier des regroupements possibles, non prédéterminés, à partir de données volumineuses, le machine learning est plus adapté.
Machine learning et réseaux neuronaux
Cela fait plus de cinquante ans qu’on utilise en apprentissage machine le principe des réseaux de neurones artificiels. C’est du deep learning, qui s’inspire des neurones du cerveau humain et leurs connexions par les synapses. Néanmoins, cela n’a rien de nouveau.
Un réseau neuronal est une succession de couches de neurones. Chaque neurone d’une couche est lié à ceux de la couche précédente (avec un poids pour chaque liaison et une fonction de transformation globale). Dans le cas d’un apprentissage supervisé, les réseaux de neurones artificiels sont entraînés en fournissant des données en entrée pour lesquelles on attend des données en sortie. L’objectif, en utilisant certains algorithmes, est d’ajuster automatiquement le poids des connexions entre neurones dans les couches intermédiaires, sans intervention humaine, pour obtenir le résultat souhaité.
Pour cela, on va passer plusieurs fois les données d’apprentissage jusqu’à obtenir des réponses satisfaisantes. Le nombre de passages dépend de plusieurs facteurs, dont la complexité du modèle, la taille des données d’entraînement et le type d’algorithme utilisé. En général, plus le modèle est complexe et plus les données sont grandes, plus le nombre de passes nécessaires pour entraîner le modèle sera élevé.
Une fois le modèle entraîné, on peut lui poser de nouvelles questions. Il sera capable de générer du texte en réponse similaire au mode d’expression d’un humain à partir des données d’entrées. Néanmoins entre l’entrée et la sortie, on a affaire à une boîte noire. En conséquence, on ne sait pas expliquer le processus qui mène au résultat.
Si l’IA peut trouver des corrélations utiles dans des regroupements de données, elle peut aussi produire des choses absurdes.
L’arrivée des transformers
Depuis les débuts des réseaux neuronaux, certaines limitations de performance machine ont progressivement été levées. Néanmoins, il restait d’autres limitations aux niveaux algorithmiques et mémorisation.
Avant 2017, les réseaux neuronaux récurrents (RNN) étaient l’idéal pour traiter des données séquentielles, comme un texte. En effet, ces réseaux peuvent apprendre à partir des données passées et prédire des données futures (la suite d’un texte). Mais ils ont certains défauts de mémorisation, ou plutôt, une mémoire limitée.
Car si les réseaux neuronaux récurrents sont très pratiques pour le traitement des données séquentielles, ils sont très difficiles à entraîner pour gérer la dépendance à long terme. Autrement dit, lorsque le sens d’un mot dans une phrase dépend d’un autre mot très éloigné dans l’expression. A contrario, les modèles à base d’architecture Transformer (les fameux transformers) ont été conçus pour cela. Ils sont plus efficaces pour intégrer le contexte d’un mot dans leur interprétation d’une séquence de données de longueur variable.
Créés dans les laboratoires de Google, ils ont révolutionné l’approche en 2017. Pour faire court, ça va plus vite à entraîner et ça marche mieux, grâce à l’usage exclusif de mécanismes d’attention. Alors que les réseaux récurrents neuronaux utilisent aussi des mécanismes de mémoire, les transformers se concentrent sur les parties les plus pertinentes des données d’entrée.
Ainsi, ils peuvent être entraînés sur des données plus volumineuses et plus variées. In fine, ils peuvent traiter des questions en entrée plus complexes et y répondre de façon relativement plus pertinente en langage naturel.
On arrive ainsi à ce qu’on appelle des grands modèles de langage (LLM : Large Language Model).
Donc le changement de paradigme de ChatGPT, ce sont les réseaux de neurones transformers qu’on doit à … Google.
Comment fonctionne un LLM basé sur un modèle transformer
ChatGPT, ou Chinchilla (DeepMind =Alphabet=Google), sont des Large Language Model (LLMs). Ils utilisent des modèles transformers pour apprendre, en quelque sorte, à lire et écrire, à partir de corpus de texte volumineux.
Mais qu’apprennent-ils ?
Les textes en entrée sont soumis à des transformations qui les découpent en unités linguistiques ou sémantiques, appelés token. La granularité des tokens peut varier, d’un mot entier à une expression ou des phrases entières, voire à une partie de mot. Il peut aussi s’agir d’un lemme linguistique, pour normaliser les mots afin que la machine les interprète mieux.
A cela s’ajoutent des techniques de world embedding, (exemple Word2Vec, GloVe et FastText, utilisés par ChatGPT), pour représenter chaque mot ou un texte sous forme de vecteurs dans un espace multidimensionnel.
Ces techniques sont utilisées pour faciliter l’analyse et le traitement des données textuelles. La proximité des mots ou des phrases dans un espace multidimensionnel sert à analyser leur similarité, prédire statistiquement les mots qui suivent ou déduire des informations supplémentaires. Une déduction toute relative. De la proximité des expressions « frère de mère » ou « frère de père » avec « oncle » vient une forte probabilité qu’on puisse les remplacer par oncle.
Quand ChatGPT répond à une question, il analyse et utilise les tokens de la phrase pour déclencher des réponses prédéfinies. Les mécanismes de cette analyse conduisent à générer un texte plutôt riche en vocabulaire et « human-like ». En effet, les réponses semblent plutôt naturelles et cohérentes.
Bien entendu, la richesse et la précision des réponses dépendent du nombre de tokens, de mots, de phrases, d’expression, tirés des données d’apprentissage qui ont été découpées pour constituer son maillage de neurones et de connexions.