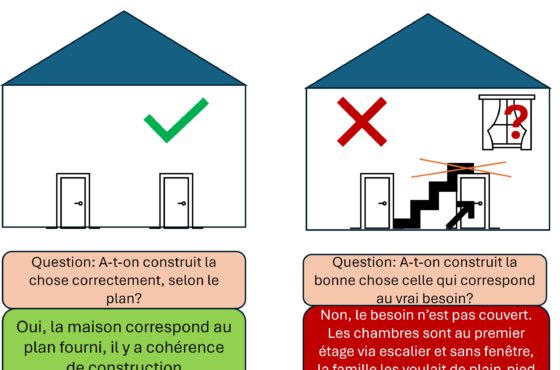
Vous modélisez en monde ouvert ou en monde clos?
Même si le mot peine à se démocratiser, les ontologies OWL sortent (un peu) de leur anonymat. Avec la reconnaissance de la nécessité de « SMART data » pour exploiter le potentiel des « Big ». Elles profitent du regain d’intérêt pour les « graphes de connaissance », ou, en bon jargon, « knowledge graph ». Parce qu’elles sont une solution pour représenter les liens entre concepts qui permettent de faire raisonner les machines, dans un monde ouvert. En pouvant exprimer beaucoup de choses dans un langage formel sur les données échangées entre plusieurs systèmes, indépendamment des implémentations.
Modéliser une ontologie OWL, ce n’est pas « penser objet avec UML»
Le World Wide Web dans son état actuel ressemble à une géographie avec de mauvaises cartes. […] Cette masse énorme de données est ingérable sans l’aide d’un outil puissant. Pour une cartographie plus précise de ce territoire, les agents de traitement ont besoin de descriptions du contenu interprétables par des machines et de ressources accessibles par le Web.
OWL Web Ontology Language Guide W3C Recommendation 10 February 2004
Toutefois, si l’approche ontologique du Web introduit un nouveau paradigme dans la modélisation des données, les similarités entre UML et OWl ont conduit malheureusement à en limiter la compréhension. On a parfois sous-estimé les différences des deux approches, pour aboutir à des résultats peu exploitables. En particulier, en essayant de traduire automatiquement des modèles UML en OWL, à des fins de réutilisation,
La première version éditée par le W3C du « OWL Web Ontology Language » en 2004, annonce l’intention derrière le langage. OWL vise à mieux cartographier les connaissances, dans un monde ouvert.
Le but d’OWL est de permettre d’échanger des contenus interprétables par des machines fonctionnant dans des systèmes hétérogènes distribués. Il s’agit de favoriser l’échange et le raisonnement entre systèmes différents, dans la mesure où le permet la sémantique formelle du langage. OWL manipulant, comme UML, des notions de classes et d’héritages, certains n’ont vu qu’un pas à franchir pour traduire automatiquement des modèles UML en OWL. Mais c’était aller trop vite en sous-estimant des différences fondamentales. Dont celle entre l’hypothèse du monde clos et l’hypothèse du monde ouvert.
L’hypothèse du monde fermé (clos) …

Figure 1NASA Earth Data Helps Scientists to Understand Our Home Planet Image Credit: NASA/Joshua Stevens; Caption by Kathryn Hansen
L’approche OWL a été développée initialement pour supporter la représentation de la connaissance à propos d’un système existant. Donc pouvoir qualifier des données, des informations, avec des métadonnées et pouvoir déduire (inférer) des connaissances de celles-ci. Cette déduction utilise les liens logiques prédéfinis entre les concepts manipulés au niveau des métadonnées.
De son côté le langage de modélisation UML, a été développé initialement pour supporter la construction d’un système logiciel. UML est plutôt orienté vers la notion de CWA (Closed World Assumption). La connaissance est implicitement vue comme complète, pour le système recherché. Tout ce qui n’est pas déclaré explicitement est présumé faux.
Ainsi, si vous ne trouvez pas de train pour un horaire précis dans votre base de données, votre système, modélisé avec UML, vous répondra qu’il n’y en a tout simplement pas à cet horaire, parce qu’il a été conçu de cette manière. UML n’est pas un langage de logique descriptive. Il n’est pas prévu pour des bases de connaissances, mais pour des bases objet (éventuellement relationnelles). Il n’est pas prévu pour un monde ouvert, mais pour un monde clos. Où finalement, ce qui n’est pas connu comme vrai, est faux.
Face à l’hypothèse d’un monde ouvert

An OWL2 ontology to express consent in relation with the GDPR.
OWL, par contraste, interprète les modèles comme ne représentant qu’une connaissance partielle du monde (OWA pour Open World Assumption). On part du principe que certaines choses peuvent être inconnues. OWL permet la définition de synonymes pour la description des classes, des propriétés, des individus. Un des objectifs d’OWL est de permettre la classification automatique. On peut aller bien au-delà des relations hiérarchiques entre classes en représentant des relations dynamiques.
A l’inverse, UML part de l’hypothèse que chaque nom a une interprétation unique, il ne fournit pas d’assistance native pour la définition de conditions suffisantes pour appartenir à une classe, ni même de classe définie par conditions et n’a pas non plus de raisonnement logique intégré. La notion d’héritage s’applique aux classes, pas aux propriétés. En UML, une classe est une sorte de namespace en soi. Si deux classes, par exemple Organisation et Personne, ont chacune la propriété nom, les deux propriétés «nom» sont différentes.
Dans UML un attribut a une portée liée à la classe, à la différence des ontologies dans lesquelles une propriété représente un concept de premier niveau pouvant exister indépendamment d’une classe. En OWL, la propriété est globale, tant qu’on ne définit ni domaine, ni portée. Par contre, si on définit la propriété « apourNom » comme ayant pour domaine Personne et pour portée (range) xsd :string, alors si on écrit qu’un individu de la classe organisation « apourNom » quelque chose, cet individu sera inféré comme … une personne.
Avantages OWL versus UML
UML a des limites en expressivité et en flexibilité par rapport à un langage de représentation des connaissances orienté ontologie. Ainsi pour donner un exemple, on peut modéliser plus simplement en OWL qu’en UML cette assertion « Toutes les transactions financières de moins de 1000 dollars sont des transactions libres de taxes ».
Un modèle UML est moins flexible qu’un modèle OWL, car une fois le modèle conçu et utilisé dans une application, il est très difficile de rajouter des paires propriété-valeur à un objet, ou changer la cardinalité d’un lien (propriété qui passe d’une valeur possible à de multiples valeurs possibles). Chaque objet a un type immuable et ne peut pas changer de classe … Alors que dans la vie réelle, tout individu peut changer de « classe ». Une PME peut devernir une ETI, un client particulier devenir également client entreprise, etc.

Le projet SAIL-ON de la DARPA,
Or aujourd’hui, nous avons besoin de systèmes qui ne raisonnent plus en monde clos avec des règles immuables. Il leur faut pouvoir intégrer de nouvelles connaissances en provenance d’autres environnements, dans un monde ouvert, ainsi que de nouvelles règles du jeu.
Le problème de l’intelligence « artificielle » : l’adaptabilité
Faire en sorte que les machines puissent prendre en compte intelligemment l’environnement dynamique et mouvant du monde réel, est d’ailleurs typiquement le problème que la DARPA (Defense Advanced Research Project Agency) voudrait voir résolu avec le programme Science of Artificial Intelligence and Learning for Open-world Novelty (SAIL-ON) (cf. lien sur l’image à gauche).
L’idée est de faire passer de la résolution de problèmes dans un monde « fermé », délimité par des données disponibles dans un environnement bien défini, à l’analyse de situations nouvelles et rapidement mouvantes.
Cela, sans forcément disposer de suffisamment de données en entrée pour s’exercer à en tirer des « patrons » statistiques. Car si un système de Machine Learning fonctionne de cette manière, il ne fait qu’indiquer une corrélation entre des faits. Cela ne le rend pas intelligent pour autant. La corrélation n’est pas l’intelligence au sens où ce n’est pas la compréhension de son environnement pour s’y adapter.
Dans une approche plus orientée vers la déduction, où on se focalise sur les liens de sens entre données pour déduire des choses nouvelles, il nous faut des modèles de représentation des connaissances qui fonctionnent sur l’hypothèse du monde ouvert, celle du monde réel.
Inconvénients OWL versus UML
C’est là tout l’intérêt et l’inconvénient majeur d’OWL : l’approche du « monde ouvert ». Pour créer des applications destinées à fournir des réponses connues sur un ensemble fermé de réponses possibles, ce n’est pas le bon choix. Si vous voulez des applications pour interroger les vols prévus au départ d’un aéroport, les livres disponibles dans une bibliothèque (et seulement celle-ci), les cours dans une faculté, UML sera plus adapté. Mais si vous voulez faire interagir des systèmes qui ne se « connaissent pas », ou réunir des informations en provenance de sources réparties pour en tirer de la connaissance supplémentaire, OWL sera plus intéressant. Pour savoir que le même livre existe dans plusieurs bibliothèques (si leurs catalogues sont accessibles en RDF), éventuellement dans une édition différente, ou chercher des livres qui traitent d’un sujet en lien.
Un avantage des ontologies OWL réside aussi dans la mise à disposition d’outils capables de raisonner sur elles. Mais ainsi qu’indiqué par le W3C dans son premier guide OWL, « construire un système de raisonnement solide et utile n’est pas une affaire simple ». Il y a des problématiques de décidabilité (terminer les calculs dans un intervalle de temps fini) des systèmes de raisonnement et aussi de grosses contradictions entre ontologies, du fait de réutilisation pas toujours cohérentes. Heureusement, il y a eu beaucoup d’évolutions depuis 2004, et les systèmes d’inférence ont eux aussi connu le renouveau de l’Intelligence Artificielle. Ce sera d’ailleurs l’objet d’un prochain article (Un monde rempli d’incohérences n’empêche pas de raisonner).
Les limites des traducteurs automatiques
Un exemple à grande échelle dans ce domaine est ifcOWL, pour le BIM (Building Information Modeling). Même s’il ne s’agit pas à proprement parler d’UML au départ, mais du langage Express, l’exemple est applicable.
Il s’agit d’une traduction automatique du standard IFC (Industry Foundation Classes), à partir d’un schema EXPRESS, vers une ontologie OWL. Le résultat est une ontologie monolithique, large et complexe, et peu exploitable. Cela en raison du grand nombre d’assertions (axiomes logiques liés aux entités) chargées et à vérifier par un outil de type raisonneur quand l’ontologie est référencée par un knowledge graph RDF.
Des réflexions sont en cours pour réutiliser des sous-ensembles, modulariser ifcOWL, mieux en repenser le contenu et la structure. Afin d’en obtenir un meilleur usage dans le cadre du Web sémantique pour l’interopérabilité entre les acteurs du secteur. Elles sont dans la « to-do list » de la feuille de route de l’organisation Building smart, pour le workflow BIM.
Le problème de la traduction de modèles UML en OWl
Reste que dans de nombreux domaines d’activité utilisant des systèmes d’information, la connaissance liée à un métier est souvent représentée par des modèles UML. Notamment par des diagrammes de classes modélisant les entités propres au domaine.
Dès lors, il semblait naturel de réutiliser la connaissance présente dans ces modèles pour réduire l’effort de construction d’ontologies. Certes, on peut automatiser partiellement le passage d’une modélisation UML vers OWL. Mais on ne peut s’abstenir d’une réingénierie des connaissances en changeant de paradigme.
Plus le modèle d’origine est complexe et important en taille, moins l’ontologie traduite sera exploitable et réutilisable dans des conditions de décidabilité, sans réingénierie. Or visiblement, beaucoup de modèles « ontologiques », construits sur la base de modèles « standards » existants, ont été d’abord des traductions littérales, alors qu’il eut fallu des traductions créatives, pour vraiment être dans la philosophie OWL.
La logique d’inférences, de réutilisation et d’interopérabilité sémantique d’OWL, nécessite de raisonner à la manière du nouveau paradigme du monde ouvert. Pour qui est habitué à concevoir dans l’hypothèse d’un monde clos, ce n’est pas une mince affaire, pas plus que de « construire un système de raisonnement solide et utile » pour exploiter ensuite de multiples représentations liées, dont on ne connait pas, a priori, les tenants et aboutissants.
Le constat est qu’il y a encore du chemin à parcourir et sans doute des choses à refaire. Néanmoins, plus nous souhaiterons des systèmes adaptables à des environnements dynamiques, plus il faudra raisonner en monde ouvert. Un environnement où rien n’est explicite par défaut et où les incohérences existent forcément entre diverses représentations du monde. Mais un monde rempli d’incohérences n’empêche pas de raisonner.