Intelligence artificielle ou data science sans conscience ?

Science sans conscience n’est que ruine de l’âme. Cette citation de Rabelais peut s’appliquer aujourd’hui à beaucoup de sujets connexes à la data science.
Il y a celui des entreprises pilotées par les données (data driven). On peut aussi traiter des architectures « data-centric » mettant l’accent sur les données et leurs modèles conceptuels comme actifs essentiels de l’entreprise. L’idée étant de construire, sur un noyau central fait de « données », des systèmes d‘information agiles et durables servant la performance globale. Ce sont deux approches de niveau stratégique et deux sujets distincts.
Néanmoins, quand on traite d’implémentation, on peut recourir dans l’un ou l’autre cas à des algorithmes de machine learning ou des solutions de représentation des connaissances et mécanismes de raisonnement. Autrement dit, nous parlons ici de disciplines liées à l’intelligence artificielle, mises au service d’un objectif commun aux deux approches. Il s’agit d’aboutir à la valorisation de données numériques, qu’on aura collectées de manière interne ou externe. Le moyen sera alors d’utiliser une science des données, supportées par des compétences et des outils.
On a besoin d‘outils tout simplement parce que le volume des données manipulées ne permet pas de se contenter de traitements manuels humains. Mais il faut injecter un peu de connaissances aux outils pour qu’ils soient utiles. Car les outils n’ont de sens que celui donné par la réflexion sur leur usage.
Une donnée ne vaut que par le sens à en tirer

Monnaie de monopoly
C’est pourquoi l’idéal de « valorisation des données » a peu de chances d’aboutir de façon satisfaisante aujourd’hui. Du moins, tant qu’on continuera à parler de « données » ou de « data science » sans avoir conscience de ce qu’il y a derrière. C’est-à-dire sans traiter deux aspects fondamentaux : connaissance et éthique. Le premier est un aspect réflexif, sur le sens de la donnée manipulée. Parce que, hors de son contexte et hors de tout questionnement, qui permette de la relier à d’autres informations, une donnée numérique ne signifie rien. Or, elle ne vaut que par son sens.
Manipuler une donnée à bon escient requiert la conscience du contexte de connaissances associé. Pour interpréter une simple mesure, il faut connaître l’unité de mesure. Il faut également avoir des références d’expertises pour savoir si quelque chose est trop élevé (ou pas). Néanmoins, pour que l’analyse soit appropriée, l’expertise nécessaire dépend du domaine considéré. Une température s’analyse selon l’unité de mesure (Celsius ou Fahrenheit) et le sujet traité (température corporelle ou météo, par exemple). Le contexte lui-même requiert souvent de recouper et lier de nombreuses informations (âge, état de santé, période de l’année, zone géographique, etc.).
La donnée brute, seule, ne vaut rien. Une fois le contexte connu, pour que la donnée puisse être valorisée, on devrait aussi savoir évaluer sa valeur d’échange. Encore faut-il pouvoir en faire une monnaie d’échange. C’est-à-dire la partager et l’interpréter facilement, indépendamment des solutions de stockage ou du code d’un programme.
La data science confrontée à la connaissance et à l’éthique

Questionner les modèles de la data science
La connaissance permet de comprendre l’information portée par la donnée numérique, stockée sous un format x ou y. Elle ne doit pas être enfouie dans des silos de traitement organisationnels ou techniques. C’est à dire : entreprise, département interne, solution, application, structure de base, structure de fichier. Or on traite plus souvent de formats de stockage et de structure de données que du sens de la connaissance associée et à quoi elle sert.
De plus, il y a forcément des limites à établir sur ce qu’on peut monnayer. Ce qui nous amène à l’éthique. En 2013, je soulignais, dans une série de trois articles autour du thème « big brother data ou big open data » la prise de conscience nécessaire de la valeur des informations privées et les dangers de la monétisation des données personnelles comme modèle économique. Ainsi que l’importance de se poser les bonnes questions sur l’usage des technologies de l’information tout au long de leur évolution (2e partie).
On peut légitimement se demander qui a le droit de posséder, voire d’annexer à des fins économiques, quelles informations. L’aspect éthique ne se restreint pas à la protection, certes indispensable, des données personnelles. On a avancé sur ce domaine (RGPD), peut-être pas tant sur les autres.
En particulier, on doit toujours pouvoir questionner les algorithmes et les modèles qu’on utilise. Car il est crucial d’être capables d’expliciter pourquoi on obtient certains résultats. Les algorithmes de Machine Learning emploient des modèles prédictifs construits sur des méthodes statistiques. Les jeux de données en entrée peuvent conditionner les sorties et conduire la machine à produire des recommandations inspirées de biais préexistants. Est-ce que les algorithmes encodent nos biais ? En effet, ils le peuvent, comme nos modèles de représentation du monde. D’où la nécessité d’en être conscients.
la data science, une clé vers un nouvel eldorado économique?

Le mirage de l’eldorado
Le machine learning, la data science, le big data, les data lakes, les data hub et autres concepts génériques ou outils supposés « data-centric » ont fait l’objet d’un engouement manifeste dans les dix dernières années. Lequel s’est traduit par de nombreux projets et/ou création de postes. De nouveaux profils sont apparus. Entre autres, nous pouvons citer ceux de data scientist (très orienté analytique ou pattern de machine learning), data engineer (très orienté solutions de traitement de données, SGBD, ETL, etc.), CDO (plus souvent orienté marketing que technologies), data protection Officer (orienté sécurité), etc.
Cela traduit sans doute l’espoir de reproduire les succès économiques des GAFAMS, BATX, NATO ou autres acteurs ayant réussi brillamment dans le domaine des technologies numériques. Car leurs modèles économiques reposent en grande partie sur l’exploitation à grande échelle de données. Lesquelles sont collectées massivement à travers tous types d’interactions entre les parties prenantes. Néanmoins, sans que ces dernières en soient informées ou en aient accepté le principe. Ce pourquoi l’encadrement législatif d’une telle collecte est devenu un sujet de politique Européenne (RGPD).
Data est le mot-clef d’un nouvel eldorado économique. Le mot anglais s’est substitué au mot français à des fins d’accentuation du terme. Mais si dans les discours marketing, la « data » semble une et indivisible, elle recouvre des problématiques d’exploitation et d’échange de données protéiformes et complexes. Les « data marketplace » qui sont envisagées aujourd’hui selon les secteurs d’industrie, ont toutes leurs spécificités liées aux métiers concernés.
Dans tous les cas et à raison, protéger, aussi bien que valoriser les données, impliquent des pratiques consubstantielles à la stratégie des entreprises.
Les données sont une affaire de gouvernance de l’information

Guide d’audit de la gouvernance, CIGREF
Ainsi gérer, valoriser et protéger les données de l’entreprise est le vecteur 4 des douze vecteurs définis par le CIGREF pour auditer la gouvernance des SI dans le guide associé de 2019. Lequel souligne « La donnée, pléthorique, interne et externe, structurée et non structurée, constitue un challenge et un actif majeur pour l’entreprise. Il convient de l’exploiter et de la protéger de manière optimale ».
Le CIGREF met en avant l’identification des données par l’entreprise et leur gestion comme un actif majeur. L’association souligne aussi la nécessité d’établir une stratégie cohérente d’usage. Elle promeut de gouverner et maintenir un référentiel des données importantes de l’entreprise et de tracer les applications qui les utilisent, la politique d’accès, la durée de conservation, le niveau de sécurité, etc. L’indispensable mise en place de processus de vérification de la qualité des données figure également au titre des bonnes pratiques.
Néanmoins, force est de constater que le CIGREF n’aborde pas quelques questions structurantes liées à la valorisation des données et leur bonne gouvernance. D’une part, dans la définition des rôles et des instances de décision à mettre en place, d’autre part, dans l’approche méthodologique de transformation de la « donnée brute » en connaissance.
Ainsi, le rôle de data steward n’apparaît pas dans le guide du CIGREF. Il est pourtant clé dans l’approche de gouvernance des données car garant de la pertinence et la qualité des données et davantage, des métadonnées nécessaires à l’achèvement des buts de l’organisation.
Comment gouverner sans clarifier la connaissance pour réduire l’incertitude?

Data interrogation
Le CIGREF mentionne bien que : « le dictionnaire des données doit être partagé et compris par les métiers et la DSI « . Seulement, comment s’assurer de la compréhension réelle des termes associés aux données par tous les acteurs ?
Il faut un consensus durable sur une description rigoureuse des concepts manipulés et leurs interrelations. Comme il faut clarifier les règles logiques qui les régissent. Une description textuelle et terminologique est insuffisante. Tout simplement car l’acception des termes chez une organisation peut signifier autre chose dans une autre. « Piloter » un projet n’est pas « piloter » un avion. De plus on risque des erreurs de traduction d’une langue à une autre. Du moins, si on manipule des labels et non des concepts décrits logiquement. Un dictionnaire peut suffire entre humains pour partager et comprendre des termes dans une organisation A. Mais l’organisation B peut avoir une autre approche des termes. Quand A et B fusionneront ou échangeront, cela posera des problèmes.D’abord de compréhension entre humains, ensuite de communication et/ou migration entre systèmes.
Dès qu’on aborde la question de l’interopérabilité de systèmes hétérogènes à large échelle, on ne peut pas se contenter de dictionnaire terminologique ou technique (CRUD). Parce qu’on peut bien comprendre les données dans un contexte et mal les interpréter dans un autre. Il faut que les représentations de connaissances soient des descriptions logiques. La définition d’un concept ne doit pas souffrir d’ambiguïté et être explicite pour une exploitation par différents systèmes et langues.
On ne peut envisager des places de marché de données sans formaliser clairement ce qui est vendu. Comment considérer d’enrichir un panel de données avec d’autres si on ne comprend pas en quoi elles sont reliées ?
Les habits neufs de l’empereur

The Emperor’s new Clothes (credit photo Kevin Dooley, licence cc-by-2.0)
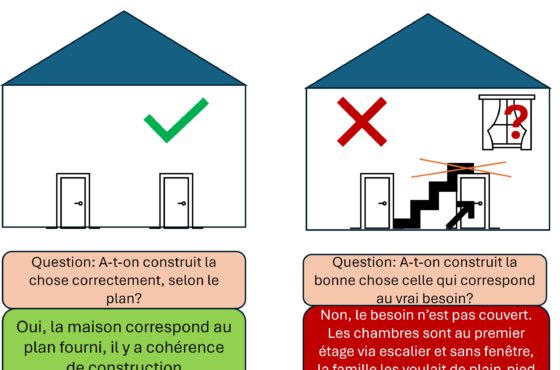
L’usage permanent du terme « données » induit une confusion entre ce qui devrait être du niveau des concepts d’information manipulés (le quoi et le pourquoi) et ce qui est une implémentation codée d’une représentation partielle de l’information. Que doit-on auditer pour vérifier que « l’entreprise a mis en place des initiatives/outils pour valoriser ses données » ou que « les outils et les compétences sont utilisés par les métiers pour leur fonctionnement et leurs projets notamment en matière d’innovation »?
Les outils n’ont pas la connaissance métier de l’entreprise « infuse ». Ils proposent des modèles plus ou moins standards pour exploiter des données sous l’angle des solutions. Les compétences portent sur l’usage des outils, pas sur l’élicitation et la formalisation des connaissances de l’entreprise.
Dès lors qu’on met en place des outils de data lake en espérant découvrir leurs usages par la suite, on s’expose à la déception. Particulièrement avec des données en entrée de mauvaise qualité et sans contexte exploitable. Il en ira pareillement avec des algorithmes de machine learning dont on ne sait pas expliciter les résultats. Pourquoi prendre le risque de découvrir après coup qu’ils sont basés sur des données d’apprentissage biaisées ou des modèles erronés? Il est bien sûr possible de créer des data hub avec des règles de mapping complexe entre structures de stockage. Cependant, sans expliciter clairement le sens en termes de logique métier de ce qu’on manipule, est-on certain de la pertinence du résultat ?
Semblable à une version moderne du conte d’Andersen « les habits neufs de l’empereur », le discours marketing habille souvent d’une étoffe extraordinaire une réalité plus décevante. Néanmoins, les outils ne détiennent pas la connaissance de la stratégie d’entreprise ou de son existant. Pas plus qu’ils ne détiennent la capacité d’innovation. Ils peuvent la servir, à condition de savoir ce qu’on veut et ce qu’on a.
Une intelligence artificielle toute relative qui n’a rien de magique

La voyante artificielle
Les outils d’intelligence artificielle utilisés actuellement pour exploiter les grands volumes de donnés, manquent cruellement de capacités de compréhension. Ils n’ont qu’un vernis de connaissance. Tel est le constat de Doug Lenat, expert en intelligence artificielle, que j’ai repris dans l’article https://www.semsimo.com/un-monde-rempli-dincoherences-nempeche-pas-de-raisonner/.
Un système de Machine Learning fonctionne avec des patrons statistiques, il ne fait qu’indiquer une corrélation entre des faits. Pour analyser la donnée dans son contexte et en déduire automatiquement des informations utiles, une approche sémantique à base d’ontologies est nécessaire, en complément. Il s’agit là d’ontologies formelles, vues à la fois comme objets de modélisation, d’inférence, et d’interopérabilité.
L’approche ne consiste pas réellement à faire qu’une machine comprenne le sens d’un concept. Ce serait la traiter comme un sujet ayant une volonté propre. Or la machine ne comprend pas intrinsèquement. Le but premier est de faire dialoguer les machines sur une échelle très large. On peut les faire interopérer à un niveau sémantique en identifiant la nature des données échangées et le contexte lié.
Si un système dispose de descriptions associées à des faits de certaines natures d’un côté, et de l’autre, une spécification formelle explicitant tous les liens et tous les axiomes d’un domaine de connaissances dans lequel interpréter ces faits, il pourra déduire d’autres faits de façon logique.
Il n’y a pas là d’intelligence implicite. Les mécanismes de raisonnement automatiques qui sont mis en œuvre reposent sur un effort d’élicitation des connaissances recourant à une formulation mathématique à base d’axiomes et de règle.
Les systèmes d’information d’entreprise interopèrent majoritairement à un niveau syntaxique, via des programmes qui manipulent des structures de données prédéfinies. Ce n’est pas un « dialogue entre machines » car elles ne se diront rien de plus que ce qui est programmé. Les codes ne déduisent pas tout seul des choses pertinentes.
Faire dialoguer les machines demande plus qu’un vernis de connaissances

Etincelle de connaissance
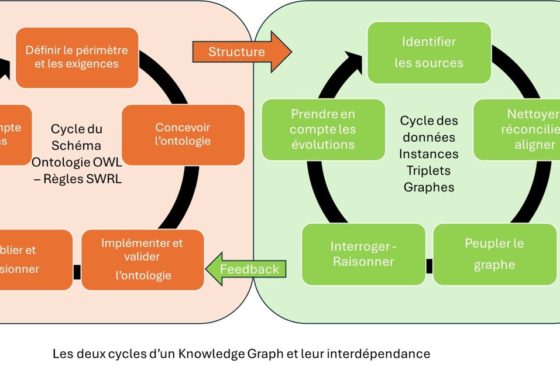
Pour que les machines infèrent des choses en s’échangeant juste des données, il leur faut des graphes de connaissances de référence. Ces graphes manipulent des modèles de métadonnées qui permettent de qualifier les données pour un usage. En rajoutant par exemple le contexte spatio temporel, de façon normée, à chaque donnée collectée, on peut mieux réutiliser de grandes masses de données pour des expériences physiques. Encore faut-il créer ces modèles en fonction de certaines connaissances. Celles dont la nécessité fait consensus pour l’usage recherché.
L’effort de création doit s’abstraire de débats terminologiques ou techniques pour aborder avec rigueur et logique la formulation des connaissances liées à une expertise. Dire que quelque chose est « une sorte de », cela correspond fondamentalement à quoi ? Qu’est-ce qui me permets de déduire quoi ? De quoi ai-je besoin pour établir un diagnostic ou pour comprendre une situation ? Quelles sont les ensembles de choses à connaître dans mon domaine – les compétences nécessaires, lesquelles sont réputées être vraies ou quelles choses étant vraies, impliquent que d’autres le soient ?
Il faut éviter de polluer cette approche immédiatement par les biais des outils ont on dispose (modèles ou bases). Ce qui serait un réflexe du registre, dans la data science, du « théorème du lampadaire » de Jean-Paul Fitoussi sévissant dans la science économique. Savoir où chercher vient après savoir quoi chercher et pourquoi. Dés lors, « valoriser les données d’entreprise », nécessite peut-être de s’interroger d’abord sur le sens des données à collecter. Ce qu’on veut et peut faire. Ce qui n’est pas qu’une affaire d’outils ou de compétences sur les outils, mais bien de gouvernance et de … modélisation des connaissances.