Comment bien éduquer un transformer ?

Un transformer peut se comporter comme une personne mal éduquée
Dans l’apprentissage profond (deep learning), une fois l’espace multidimensionnel créé avec toutes les représentations des tokens calculées, les neurones et les connexions entre couches de neurones établies par l’apprentissage initial, on a affaire à une boîte noire entre l’entrée et la sortie.
Cela signifie que le modèle ne peut pas expliquer comment il arrive à ses résultats. Le processus de prise de décision est caché. Mais il y a des probabilités que le système obtenu réplique des types de tournures ou de réactions typiques de son corpus d’entrée.
Au regard du corpus initial de ChatGPT, on peut pressentir un premier biais culturel. Il y a également une probabilité non négligeable d’avoir des réponses peu policées. De plus, personne ne se risquerait à dire que les contenus entiers d’Internet, de reddit, de livres de fiction, sont des sources de véracité totale et de discussions polies et mesurées ne reposant que sur des preuves tangibles et des raisonnements sans défaut.
Pour rendre un transformer poli, rien de tel que le renforcement humain (RLHF)

Cependant, le modèle peut continuer à être entraîné pour améliorer ses performances. En effet, il est possible de repartir du modèle initialement fourni et pré-entrainé sur un très grand corpus pour l’affiner (fine-tuned) sur un domaine plus réduit et plus spécifique. Ainsi, on générera des réponses plus pertinentes. On arrive aux méthodes d’apprentissage par renforcement (reinforcement learning). Le principe est qu’une fois le système entraîné sur ses données initiales d’apprentissage, on simule son comportement dans son environnement cible, et on va chercher à optimiser ses réponses ou actions en fonction de récompenses positives ou négatives.
On peut utiliser un autre algorithme d’IA comme on peut utiliser une approche dite RLHF (Reinforcement Learning with Human Feedback), utilisée pour ChatGPT (pour en savoir plus : https://huggingface.co/blog/rlhf) , voire combiner les deux. Cela va clairement donner une apparence plus humaine aux réactions du robot. Néanmoins, là aussi, on pourrait entraîner le système à avoir les biais de ses entraîneurs.
Pour rendre un transformer plus intelligent, on peut aussi vouloir lui donner des capacités de raisonnement sur des connaissances structurées.
Les transformers n’ont pas de réelles capacités de raisonnement
Aujourd’hui, les grands modèles de langage basés sur les transformers ont des problèmes avec des tâches de raisonnement, même simples. Cet article l’illustre bien avec quelques exemples.
A contrario, ils peuvent impressionner par leurs connaissances. Ainsi, en théorie, un agent conversationnel type ChatGPT, ou BARD, peut obtenir un diplôme en comptabilité ou pourquoi pas, une certification sur un référentiel côté. Si son corpus a engrangé presque tout ce qui a été écrit sur le sujet, c’est très vraisemblable. A partir du moment où on ne fera que vérifier la capacité à citer des aspects de la documentation des pratiques, il a en effet des probabilités non négligeables de réussir.
D’ailleurs, ChatGPT peut très bien être un interlocuteur idéal pour du support de premier niveau. Du moins, s’il existe des FAQs. Mais dès qu’il s’agira de comprendre réellement un problème qui diffère de questions bateaux ou qui suppose un peu de logique, le beau parleur atteindra ses limites. Il pourra même dire n’importe quoi, ce qui peut énerver un client, ou un professeur.
Donc, est-ce que ChatGPT sait remplacer un sachant ? En général, non. Parce qu’il ne saura pas appliquer et restituer ce savoir dans le cadre d’un cas pratique avec beaucoup d’éléments contextuels en interactions. Pas plus qu’un étudiant qui aura triché ou appris par cœur une chose sans la comprendre. On ne peut pas compter sur ce type d’outils pour organiser et capitaliser la connaissance d’une organisation.
De plus, la majorité des entreprises n’ont pas la capacité d’entraîner des grands modèles de langages de type transformers.
Combiner un modèle pré entraîné avec un knowledge graph : quel intérêt ?
Néanmoins, on peut prendre un modèle pré-entrainé et l’adapter, avec de l’apprentissage renforcé à un domaine de connaissances spécifiques. On ne sort néanmoins pas de la probabilité d’avoir des erreurs dans le processus de décision, ou d’avoir du mal à l’expliquer.
En revanche, on peut améliorer l’expérience utilisateur en interrogant un graphe de connaissance en langage naturel via une interface de type chatbot LLM. Le chatbot saura traduire la question en une requête (type SPARQL) sur le graphe. Ce dernier retournera des informations précises. Charge alors à l’interface de les écrire en langage naturel pour les utilisateurs.
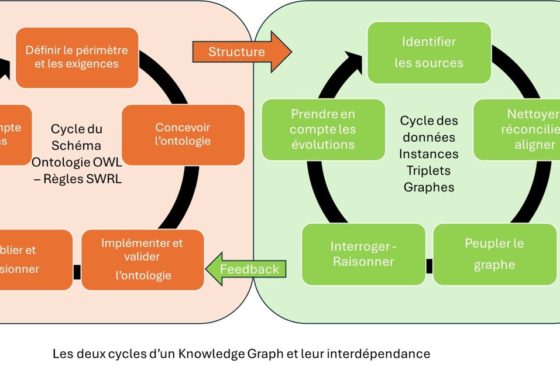
En utilisant des ontologies formelles pour modéliser les domaines de connaissances de l’entreprise, on peut ainsi insuffler beaucoup plus de capacités de raisonnement à un modèle tel que ChatGPT ou autres. On peut aussi combiner cela avec un outil tel Whisper, d’Open AI, pour une interrogation orale.
Pour des réponses se basant sur des éléments exacts et avec des capacités logiques, l’IA symbolique est l’élément d’intelligence de plus à insuffler à ces modèles de génération de langage naturel. On peut utiliser les knowledge Graphs et OWL, ou autre chose. Par exemple, Wolfram Alpha, ce que démontre Stephan Wolfram dans cet article.
A présent, s’il s’agit de représenter la connaissance spécifique à une entreprise, mieux vaut qu’elle spécifie ses propres ontologies, tout en réutilisant ce qui existe au juste nécessaire, et crée ses propres knowledge graph. Car la modélisation de sa connaissance est un de ses actifs clé valorisable.
De la même manière, pour alléger le travail de formalisation, on peut envisager d’utiliser des réseaux neuronaux transformers. Ils peuvent être utiles pour proposer une première classification. Mais ils ne pourront pas remplacer l’expertise humaine et pas plus la traduire en termes logiques.