Les données d’apprentissage : l’alpha et l’omega d’un transformer
2022-Alan-D-Thompson-AI-Bubbles-Rev-6
Le problème des données d’apprentissage
De l’épisode 1 on peut conclure qu’un agent conversationnel basé sur un grand modèle de langage ne raisonne pas. Il joue sur des similarités textuelles, traduites dans un espace vectoriel. La façon même de répondre, de pouvoir reproduire un style, dépend de ses données d’apprentissage. Peut-on dès lors réellement utiliser le terme intelligence à son sujet ? En tous cas, ses capacités découlent de la nature des données sur lesquelles il a été entrainé.
Suivant la distribution statistique des mots dans le corpus d’apprentissage en entrée, un LLM à base de modèle transformer répondra plus ou moins correctement à certaines questions. ChatGPT peut terminer la phrase « The first person to walk on the Moon was ? » en répondant “Neil Armstrong.” Il n’a pas compris la question, mais construit une réponse plausible qui sonne juste. Entrainez le modèle sur un très large site complotiste et il pourrait vous dire qu’aucun humain n’a mis le pied sur la Lune.
Plus on arrive sur un domaine d’expertise peu représenté dans son corpus d’origine, plus il peut avoir des « hallucinations ». En fait, c’est un manque de représentations de sujets dans l’espace des éléments de langage sur lesquels il sait discourir. Il peut inventer en retour, mais pas distinguer le vrai du faux.
Bien parler ne signifie pas parler vrai
Ainsi, ChatGPT peut vous donner des réponses fausses et convaincantes car semblables à l’expression d‘un humain bien éduqué. Il ne saura pas faire des opérations mathématiques complexes, car il n’a pas été entraîné sur ces symboles et il ne comprend le sens relatif d’aucune mesure. Il peut vous faire de beaux exemples de code, ou de poésie, ou de fictions, ou de croyances complètement erronées. S’il a ce genre de choses dans ses données d’apprentissage, il saura en reconnaître les signes et produire des signes similaires.
Pour qu’un LLM soit performant, il a besoin d’énormément de données en apprentissage. Couvrir le plus possible de textes et de contextes lui permet de se constituer le maillage neuronal nécessaire à interpréter correctement des textes multilingues en entrée.
LLM : la guerre des titans

Peut-on mesurer ce qu’il faut de données en entrée pour créer l’illusion d’une expression humaine variée avec un vocabulaire et des expressions relativement riches et une connaissance assez étendue de beaucoup de définitions ? Oui, mais les mesures varient.
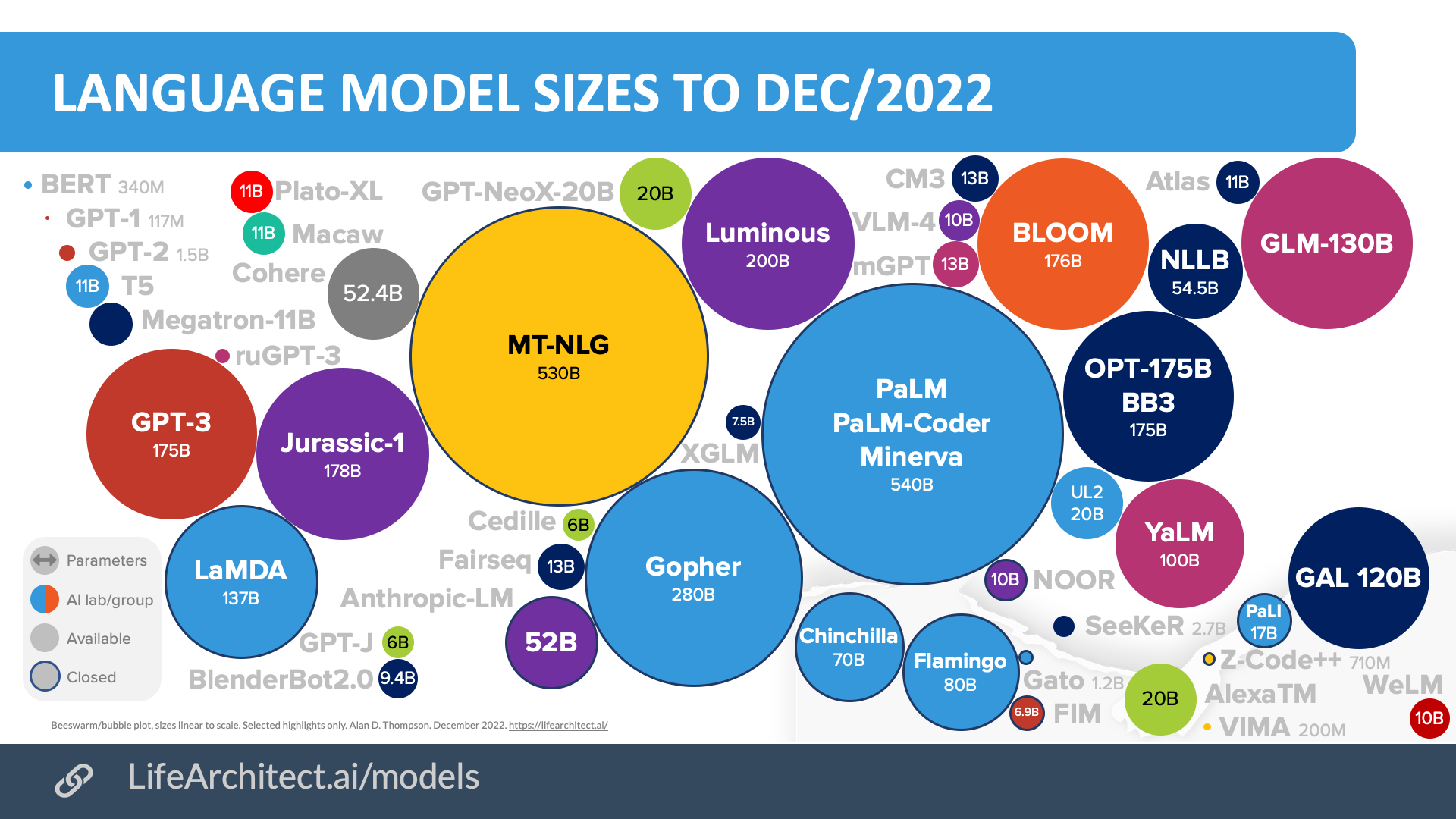
Quand on parle d’un modèle avec X milliards de paramètres, en gros, on parle du nombre de connexions entre neurones. ChatGPT est un modèle à 175 milliards de paramètres. Combien faut-il de données pour entraîner un tel modèle ? Open AI a formulé sa « loi » à ce sujet (Kaplan Scaling Law) en 2020. Il faudrait 1,7 token par paramètre, soit 300 milliards de tokens à utiliser pour entraîner ChatGPT.
En 2022, Deepmind, filiale de Google proposant chinchilla, concurrent de GPT-3, formulait une nouvelle loi. Son axiome sur le nombre de données optimal est de 20 tokens par paramètre. En d’autres termes, pour être vraiment efficace, chatGPT aurait eu besoin de 11 fois plus de données d’apprentissage qu’on pensait précédemment nécessaires …
A noter que le modèle PaLM de Google est un modèle à 540 milliards de paramètres… (Gopher 280 milliards).
Pour entraîner des transformers, il faut de gros corpus, beaucoup d‘efforts de nettoyage de données et d’apprentissage par renforcement. Mais surtout, il faut l’accès à une énorme puissance machine (pour ChatGPT un super ordinateur avec ~10,000 GPUs et ~285,000 CPU cores). Autant dire que tout le monde n’est pas équipé et que c’est énergivore et peu écologique.
Donc d’un côté, cela devient une guerre économique où seuls les titans du Web peuvent ravir la victoire. De l’autre, ainsi que le dit Jesse Doge de l’Allen Institute for AI dans cet article « l’IA peut aider à lutter contre le changement climatique, tant qu’elle ne l’aggrave pas ».
L’exemple du corpus de ChatGPT
Alan D. Thompson, dans son blog lifearchitect.ai, fournit une analyse d’ensembles de données utilisés pour un grand nombre de modèles transformers.
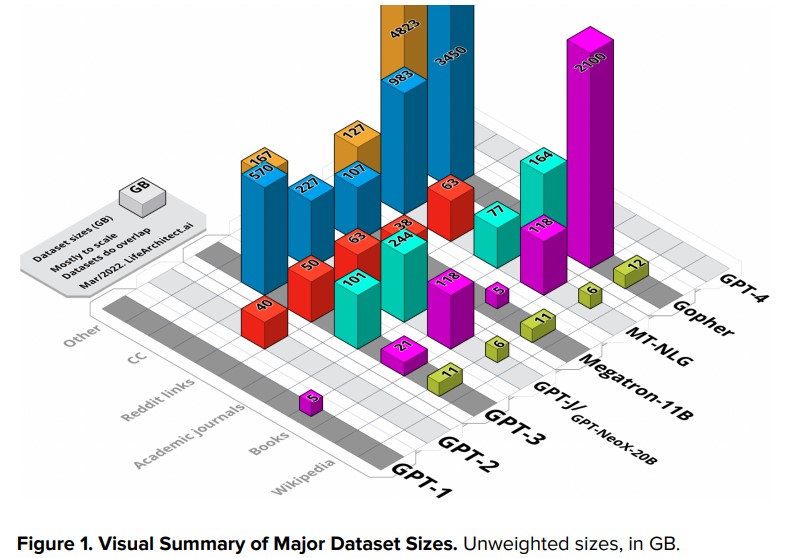
Source Alan D.Thompson, what’sin my AI?
La majorité des données (environ 60%) seraient issues de pages d’Internet, via common crawl. Cette initiative de l’Allen Institute for AI indexe entièrement et régulièrement le contenu des sites Internet et met le résultat à disposition des chercheurs gratuitement.
Pour en tirer du texte exploitable, il faut le filtrer de codes Javascript et autres.
20% et plus des données viennent d’un ensemble constitué par Open AI à partir du forum reddit. Lequel contient toutes sortes de textes avec des sous-communautés très sujettes à controverses. Mais Open AI n’a gardé que les posts ayant reçu plus de trois votes positifs. Cela vaut ce que ça vaut.
Une vingtaine de pour cent vient de deux corpus de livres respectivement nommés « Books1 » et « Books2 ». Cela a fait beaucoup travailler les imaginations car Open AI est resté discret à ce sujet. Il y aurait des livres, des articles de journaux et des articles de recherche.
Certains ont même évoqué des livres en provenance d’une plate-forme d’autoédition et des livres en provenance de Bibliotik, un site de torrents pour les fans d’ebook. Dans tous les cas, quelle que soit l’origine, elle pose deux questions. L’illégalité du téléchargement au regard du copyright ou le type de biais induits par certaines sources.
Le reste (moins de 3%) serait en provenance de Wikipedia en version anglaise, qui est probablement la source ayant fait l’objet le plus de curation.
Le corpus d’entrainement de Chat GPT s’arrête fin 2021.