
Les transformers et les aspirations des titans du Web
.jpg)
Vers les approches neurosymboliques
L’étape suivant les modèles transformers semble de plus en plus s’orienter vers une combinaison d’IA symbolique et de réseaux neuronaux. Il s’agirait d’approches « neurosymboliques ». Dans ce contexte, il n’y a rien d’étonnant à ce que les géants du Web, tels que Google, Microsoft, FaceBook… développent depuis un moment leurs knowledge Graphs. Ils ont poussé pour ce qu’un vocabulaire commun (schema.org) serve à annoter les pages Web (en RDFA ou JSON-LD) avec des métadonnées se référant à ce vocabulaire.
On peut imaginer déjà le prochain mouvement. Il pourrait consister à coupler les chatbot de dernière génération avec les Knowledge Graph de ces titans. Reste que ces knowledge Graphs sont actuellement davantage des données liées avec un vocabulaire rudimentaire que des bases de connaissances avec des ontologies computationnelles. C’est-à-dire avec un langage logique de représentation des choses qui permet de structurer le dialogue avec la base et obtenir des réponses précises et correctes.
Mais il est sans doute préférable que le Knowledge Graph de l’entreprise … reste le knowledge graph de l’entreprise, et pas délégué à une GAFAM.
On peut certes envisager de renforcer un système pré-entraîné tel que ChatGPT à partir d’une base de connaissance externe. Ainsi, il affinerait ses réponses grâce à l’acquisition de cette expertise (reinforcement transfer learning). Mais est-ce la meilleure solution ?
Les transformers sont confrontés à une incertitude juridique et de futurs coûts de mise en conformité
Les données d‘entraînement de ChatGPT posent déjà une question non négligeable sur le fait d’avoir absorbé bon nombre de documents qui pouvaient faire l’objet de copyright. Quand vous écrivez un tutorial sur une page web, ou un article, il y a un principe de droit d’auteur. Ce tutorial néanmoins pourrait être réutilisé par ChatGPT des millions de fois. Même si c’est par petits bouts plus ou moins large, pour répondre à des utilisateurs. Le résultat ne fait aucune référence à son origine.
Comment dès lors faire la preuve de l’origine ou être assuré de ne pas violer un copyright ? En théorie, ce n’est pas facile, l’IA oubliant les sources d’apprentissage. Toutefois, ces sources pourraient apparemment refaire surface de manière assez précise. En tous cas, pour stable diffusion (stability AI, qui utilise un modèle inspiré du modèle transformer GPT) et Imagen (Google), une équipe de chercheurs du MIT a montré fin janvier que l’IA pouvait ressortir une photo identique à une source, et non générée, photo soumise au copyright.
De toute façon, techcrunch avait déjà souligné l’usage de données sous copyright BBC par GPT-3 en 2019. On trouvera sur la page de Wikipedia concernant GPT-3 un paragraphe instructif. « Dans sa réponse à une demande de commentaires de 2019 sur la protection de la propriété intellectuelle pour l’innovation en intelligence artificielle de l’Office des brevets et des marques des États-Unis (USPTO), OpenAI a fait valoir que « En vertu de la loi actuelle, la formation de systèmes d’IA [tels que ses modèles GPT] constitue une utilisation équitable« , mais, « étant donné l’absence de jurisprudence sur ce point, OpenAI et d’autres développeurs d’IA comme nous sont confrontés à une incertitude juridique et à des coûts de mise en conformité importants ».
Attention aux aspirations des titans
Dans ces conditions, il est évident qu’une entreprise doit faire attention à sa façon d’interagir avec l’outil. L’usage de l’API pose d’ailleurs une question, même si on ne donne que des réponses en provenance d’une knowledge base,. Etes-vous sûr de ne pas contribuer à un apprentissage par renforcement?
Il ne faut pas oublier le principe de l’apprentissage par renforcement humain. Formulé par le robot lui-même, cela donne la phrase suivante. »ChatGPT est conçu pour apprendre et s’améliorer à mesure qu’il reçoit des informations et des corrections. Il peut donc utiliser les corrections faites par un utilisateur pour améliorer sa réponse à un autre.«
Si le système ne tourne pas sur vos serveurs en local, vous pouvez très bien le nourrir pour d’autres utilisateurs. En particulier, une entreprise qui ferait interagir sa propre base de connaissance avec l’agent conversationnel s’exposerait à ce que ses données soient diffusées et réutilisées largement.
La solution pourrait être celle qu’envisage Tim Berners Lee. Un futur du Web où chacun aurait son serveur stockant ses données personnelles et son propre assistant d’intelligence artificielle.
En attendant, il est légitime de s’interroger sur les aspirations de données, personnelles ou pas, des géants du Web. Tout en questionnant aussi les coûts et les impacts d’un futur où chacun aurait son jumeau numérique, en théorie protégé, sur son propre serveur.
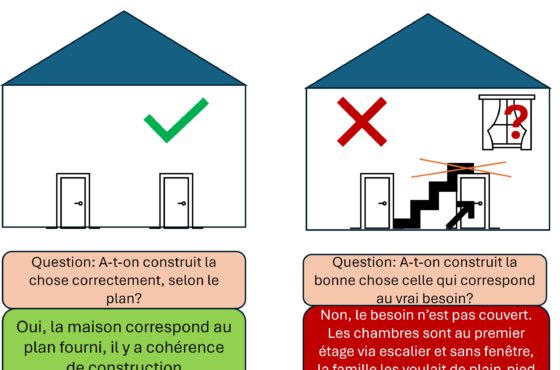
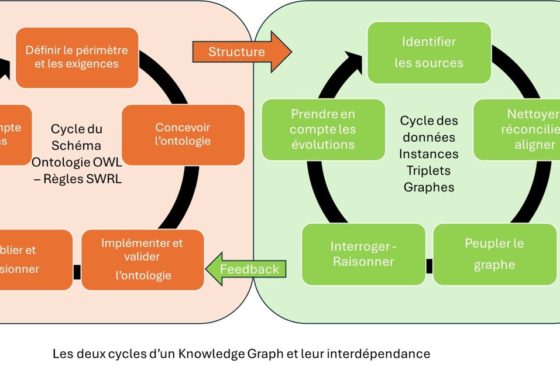

[…] Pourquoi doit-on se soucier de ce qu’on échange avec un chatbot transformer ? […]