
Home / Architecture d'Entreprise, ingénierie des connaissances, Intelligence Artificielle, KnowledgeGraph, ontologies / Meilleures pratiques pour les deux cycles de vie d’un Knowledge Graph
Meilleures pratiques pour les deux cycles de vie d’un Knowledge Graph

{kind=link}
Knowledge Graph : une architecture de description de la connaissance
Un knowledge Graph c’est une base de connaissance structurée avec des informations reliées. La conception de ce graphe donne naissance à une spécification formelle, une ontologie. C’est le squelette qui donne structure et sens aux données qui s’y réfèreront dans des ensembles de données. Dans un monde ouvert, l’organisation qui publie la structure ontologique, peut être distincte des organisations qui la réutilisent pour leurs besoins. De nombreux ensemble de données peuvent se référer à une ou plusieurs ontologies communes, tout en ayant des cycles de vie d’évaluation, de nettoyage et de mise à jour des données différents.
Quand une organisation décide de construire un knowledge Graph, elle doit se poser naturellement des questions sur le périmètre de représentation visé, l’usage prévu, les sources d’information dont elle dispose, l’architecture de la cible, les moyens de validation et de maintenance.
Construire un Knowledge Graph est définitivement une question d’architecture de la connaissance. Que sait-on ? Que veut-on savoir ? De quelles sources dispose-t-on ? Ces trois questions simples révèlent vite qu’un Knowledge Graph est avant tout une architecture de description d’un système. Dès lors, ce système peut être l’entreprise (voir mon article Knowledge Graph et Architecture d’Entreprise) ou un système logiciel, ou … ce qu’on veut, du moment qu’il y a intérêt à formaliser logiquement la connaissance dudit système.
La spécificité des knowledge Graph c’est d’être à la fois des réponses pour relier des ensembles de données dispersés avec une véritable approche d’interopérabilité sémantique et pouvoir raisonner sur ces données. D’une part, ils permettent de qualifier intelligemment (stricto sensu, de manière intelligible) la nature du rapprochement qu’on peut faire entre données. D’autre part, ils sont sources de raisonnements à base de déduction, totalement explicable sur la base de règles prédéfinies (explainable AI). Ils permettent des inférences logiques et non des analyses statistiques de corrélations possibles.
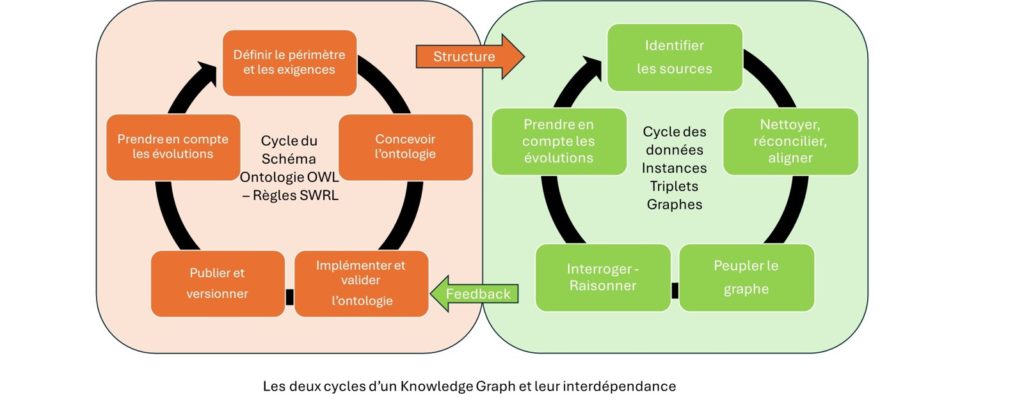
Deux cycles de vie interdépendants : l’ontologie et les données
Dans un knowledge Graph, on a deux types de cycles de vie à considérer, qui se nourrissent l’un l’autre. Le cycle de vie de l’ontologie, et les cycles de vie des graphes d’ensembles de données qui s’y réfèrent. L’ontologie elle-même est à la fois un artefact logiciel, implémenté dans un langage de logique descriptive tel qu’OWL, compréhensible par les machines, et un artefact de connaissance représentant l’expertise d’une communauté. De facto, elle a un cycle de vie de développement qui nécessite des expertises à la croisée de l’ingénierie logicielle, de l’ingénierie des connaissances et de la logique formelle.
De plus, cette ontologie peut devoir être « augmentée » par des règles additionnelles (avec un langage comme SWRL, par exemple). Sous-estimer cette complexité produit des ontologies trop superficielles pour être réutilisées. La sur-estimer, en revanche, peut bloquer tout développement en agitant la courbe d’apprentissage comme un repoussoir. Or, apprendre à structurer ses informations est certes exigeant, mais comprendre après coup des données piégées dans des systèmes legacy l’est bien davantage.
Si votre ontologie structure vos graphes, encore faut-il pouvoir les alimenter d’informations fiables, pertinentes, propres. Ces dernières sont dispersées, sous forme de données plus ou moins qualifiées avec des métadonnées de schéma, dans des formats et des outils de stockage très variés. Pour les en extraire correctement et les relier à votre représentation ontologique, vous retrouvez la logique même de la Business Intelligence : la transformation de données brutes en informations actionnables. A ceci près que vous allez intégrer des aspects sémantiques en plus et des considérations propres à la manipulation de graphes : visualisation, navigation, interrogation, maintenance, évolution, raisonnement déductif… autant de dimensions qui appellent des choix explicites d’architecture.
Néanmoins quels que soient vos choix d’architecture ils seront guidés par la structure de description de vos connaissances, les sources dont vous disposez, et le cycle de vie des données que vous manipulez. Si vous avez à interroger la qualité de votre ontologie et gérer ses versions, de la même manière, vous aurez besoin d’évaluer la qualité de vos données et vous interroger sur leurs provenances, leurs transformations, leur niveau de confidentialité, leur temporalité, et comment les maintenir à jour.
Pourquoi un Knowledge Graph ? La question avant les outils
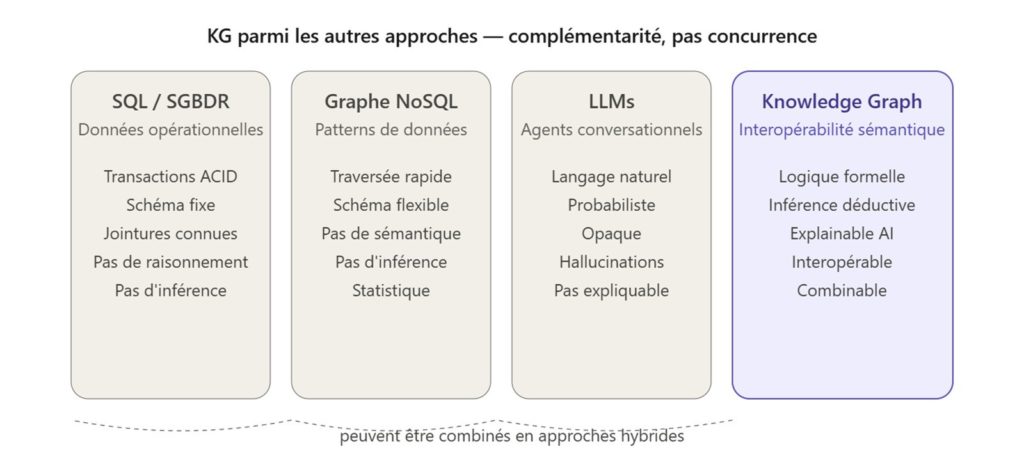
Quand on pose la question « pourquoi un Knowledge Graph plutôt que des bases de données relationnelles, du NoSQL, des LLMs ou de l’agentic AI ? », on réduit d’emblée le débat à un choix technologique. Cela n’est peut-être pas une bonne approche de questionnement et ce pour deux raisons. La première étant qu’avant de s’interroger sur les technologies, il est bon de s’interroger sur la création de valeur recherchée pour les choisir au mieux. La seconde raison est qu’il ne s’agit pas que de technologies, mais d’avoir une réflexion d’ensemble structurée sur les informations qu’on manipule, et à quelles fins, ainsi qu’une gouvernance des données
De nombreux échecs de projets pilotés par l’excitation de la découverte de technologies sans en structurer les bénéfices jalonnent l’histoire de l’informatique. On aurait pu apprendre de ces échecs, mais on ne fait pas mieux aujourd’hui qu’hier. Paradoxalement, la peur de rater un virage, Agentic AI ou Knowledge Graph, peut conduire à très mal le prendre. Par ailleurs, en ce qui concerne la gouvernance des données, il me semble plus pertinent ici de parler d’intelligence de l’information qu’on veut voir comprise par les machines. On ne peut pas gouverner des données si on ne comprend pas à quoi elles correspondent et comment les rapprocher pour les interpréter.
Si des bases de données relationnelles ou des LLMs ou des graphes types Neo4J répondent bien au stockage de données opérationnelles, à des agents conversationnels, à de la recherche de pattern de données sur des statistiques, ils sont des moyens pour d’autres fins que les knowledge Graphs. D’ailleurs, ils peuvent être combinés, dans des approches hybrides exploitant leurs avantages respectifs et réduisant leurs contraintes.
Ce qui manque encore pour atteindre la maturité industrielle
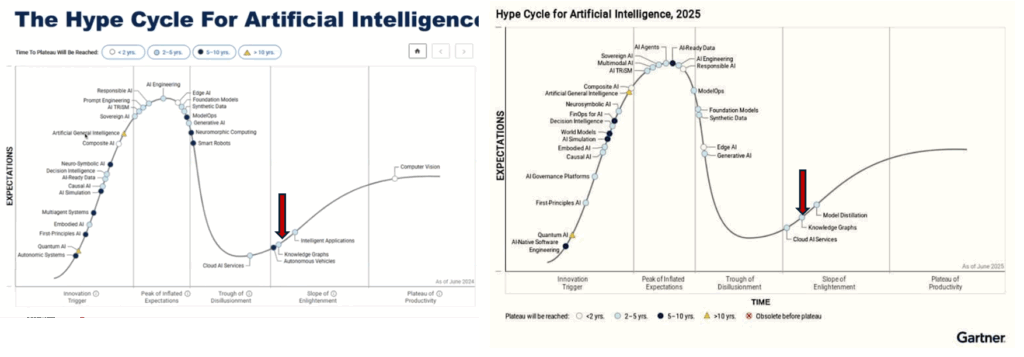
Le Gartner publiait en 2024 une hype curve où les knowledge Graph grimpaient le chemin de l’illumination et devaient atteindre le plateau de productivité en moins de deux ans. Néanmoins, en 2025, force était de constater qu’ils étaient au même endroit : celui où on a une deuxième génération de produits et quelques services accolés. Pourtant, les cas d’usage ne manquent pas : systèmes de diagnostics, détection de fraude et analyse de réseaux de transaction pour le blanchiment d’argent, calculs de taxes élaborés, recherche biomédicale et découverte de médicaments, enrichissement de moteurs de recherche e-commerce, assistance à la décision stratégique par visualisation de relations complexes …
Alors, que manque-t-il aux knowledge Graph pour atteindre le « plateau de productivité » ? Peut-être certains outils plus industriels, plus de services d’expertises (avec des ontologues), et le partage de meilleures pratiques. Combler ce déficit d’outils, d’expertise, de pratiques partagées, est un travail collectif. C’est dans cet esprit que j’ai commencé à documenter les leçons apprises sur le terrain, sous forme de bonnes pratiques. Sans engagement de publication régulière, le tout étant tributaire de mes disponibilités, mais avec l’ambition de couvrir le plus d’issues ou de questions régulièrement rencontrées dans mon expérience. A ce jour, j’ai publié sept articles de bonnes pratiques, dont vous trouverez les liens ci-dessous. J’y ajoute d’ores et déjà quelques titres d’articles en préparation dont les liens seront ajoutés au fur et à mesure de leurs publications.
La série de bonnes pratiques : un guide de lecture
- Bonne pratique ontologique n°1 : le pragmatisme philosophique
- Bonne pratique ontologique n°2 : des questions de compétences
- Bonne pratique N°3 : la réutilisabilité et l’alignement
- Ontology Design Patterns : la modularité comme principe de réutilisabilité
- Architecture multi-niveaux d’un réseau connecté
- Les ontologies de fondation
- Pourquoi une couche sémantique ne remplace pas un raisonneur (ou le problème de la validation logique de l’ontologie)
- Tester l’adéquation sémantique de votre ontologie aux questions métier
- Utiliser les knowledge Graph à bon escient (cas d’usages industriels représentatifs)
- Les requêtes SPARQL fédérées pour interroger plusieurs Knowledge Graph
- Les virtual Knowledge Graph pour atteindre l’interopérabilité sémantique en entreprise
- Gérer la provenance et la traçabilité des triplets.
- Créer votre pipeline d’ingestion et de contrôle pour nourrir proprement vos KG
- Capturer et représenter l’incertitude avec les ontologies
- Fournir des interfaces adaptées : Visualisation d’ontologies et expérience utilisateur
- Quand et pourquoi utiliser des LLMs avec des ontologies ou des knowledge Graphs
- Knowledge Graph et problématiques spatiotemporelles
- Gouverner l’’évolution des ontologies et documenter les choix
- Etendre les ontologies avec des règles sémantiques
- Considérer les ontologies pour la maintenabilité des développements logiciels