Pour en finir avec le mythe de la tour de Babel numérique


La tour de Babel, mythe du langage unique brouillé
le rêve de la langue unique
La tour de Babel, c’est le mythe de l’échec des hommes à garder un langage universel. Punition de l’hybris, importance de la diversité, inaccessibilité de la connaissance pleine et entière, nécessité de s’accorder pour les grands projets, les interprétations sont multiples.
Il est inutile d’en revenir aux références bibliques pour expliquer pourquoi les hommes ne parlent pas tous la même langue. Le langage s’adapte aux besoins. Vocabulaire et grammaire sont des outils de communication pour véhiculer les signaux importants, dans un contexte donné. Selon la culture d’un peuple, l’histoire, la région, se développent des mots intraduisibles dans d’autres langues. Parfois, ils s’exportent tels quels, raccourcis utiles pour traduire des idées complexes.
Les échanges commerciaux, ainsi que malheureusement les guerres, ont enrichi les vocabulaires. Cet enrichissement est une bonne chose. Une langue ne devient morte que lorsqu’elle n’évolue plus en se métissant avec des mots issus de vocabulaires différents. Construire dès lors un langage universel, unique et vivant, supposerait de bloquer le temps. Et gommer les contextes spécifiques d’expression et l’appartenance à des héritages.
La langue suit l’évolution des hommes et leurs besoins de communication. Pourquoi en serait-il différemment pour les technologies? Pourquoi y aurait-il un langage universel et unique des TIC?
Les deux difficultés de communication inhérentes aux Systèmes d’Information sont entre les parties prenantes et entre les applications
![Par matt smith [CC BY-SA 2.0 (https://creativecommons.org/licenses/by-sa/2.0/)]](https://www.semsimo.com/Criquets/wp-content/uploads/2017/06/Perspectiivematt-smith-cc-by-sa-2.0-300x225.jpg "Photo par matt smith [CC BY-SA 2.0 (https://creativecommons.org/licenses/by-sa/2.0/)], via Flickr")
La communication : une affaire de points de vue?
Depuis les débuts de l’informatique en entreprise, la complexité des systèmes d’information tient à deux difficultés principales. D’une part, celle de faire communiquer différents acteurs, les parties prenantes des projets, toutes les parties prenantes, clients y compris, ayant des visions et des vocabulaires différents, autour des besoins à satisfaire et des solutions pour y parvenir. D’autre part, celle de faire communiquer les différentes solutions finalement construites. C’est-à-dire des applications ayant des langages informatiques et des vocabulaires de données différents. En effet, cette communication est indispensable pour pouvoir supporter les processus d’échange d’information de l’organisation de bout en bout.
La deuxième difficulté découle souvent de la première.
Curieusement, ces deux difficultés de communication semblent en passe d’être redécouvertes à l’ère du «digital». Il est d’ailleurs amusant de voir combien «digital» ou «data» sonnent mieux aujourd’hui, en France, que numérique et données. On en oublie presque les termes technologies, informatique et information. Une subtilité linguistique, dans la grande transformation du numérique annoncée …
Mais l’évolution de langage apparente ne devrait pas masquer le fait que les problématiques essentielles sont restées les mêmes. Il y a toujours des solutions informatiques derrière le terme numérique. Il reste toujours un chemin à construire entre manipuler des données et obtenir des informations utiles.
La vitesse n’est pas toujours la pertinence

A écouter de nombreuses sirènes, beaucoup de choses seraient plus faciles, dans un monde hyper connecté. Grâce à de nouveaux moyens d’échanges d’information, il serait possible d’innover rapidement avec succès, via des plateformes numériques d’intermédiation flambant neuves et orientées utilisateurs (enfin!). Ça n’est que partiellement vrai et encore, pas pour tout type de besoins.
Dans un environnement concurrentiel, il y a certainement plus de prise en compte des exigences des utilisateurs de la part des éditeurs. En particulier, les interfaces des outils logiciels ont été globalement améliorées tant pour leur convivialité et facilité d’usage que pour leur adaptabilité à différents supports et leurs performances.
Certes, les données circulent plus vite. L’information en est-elle pour autant plus pertinente? Certes, on peut mettre en place des solutions plus rapidement, à moindre coût. S’intègrent-elles plus facilement avec l’existant des données, s’il y en a un? Peut-on exploiter la masse de connaissance acquises par l’organisation et dont dépendent beaucoup de choix, en ne faisant qu’ajouter des briques indépendantes, sans lien de sens? Les solutions numériques, dites innovantes, répondent-elles vraiment aux besoins liés aux objectifs de l’entreprise? Comment les choisir pour avoir la couverture optimum et qui doit les choisir?
Oui, il est essentiel aujourd’hui d’avoir un ensemble d’applications agiles pour répondre à un environnement mobile, réactif.
Mais il s’agit toujours de gérer un système d’information avec une infrastructure informatique derrière, hébergée ou pas. C’est à dire collecter, stocker, traiter et distribuer de l’information entre plusieurs acteurs. Il ne s’agit pas de choisir et manipuler des objets intangibles d’un mouvement de doigt, de carte bleue, ou de baguette magique sur une carte holographique. Nous n’en sommes pas là.
Derrière le numérique, il y a toujours la trinité informatique, information et communication
], via flickr")
communication
Les solutions ne se construisent pas ex nihilo, pour répondre exactement aux usages souhaités. Si les hommes parlaient tous le même langage et s’accordaient sans effort sur le sens des concepts abstraits, l’humanité aurait certainement évolué autrement. Les systèmes d’information seraient aussi moins complexes.
Il y a une forme de naïveté à croire qu’en renommant les choses, on en change la nature. Il n’y a pas une « famille du digital » à opposer à une « famille des systèmes d’information» dans l’entreprise. Ce serait une erreur stratégique de le croire. Derrière les services numériques, il y a un ensemble d’applications informatiques et un ensemble d’initiatives et de projets. Tous utilisent, ou pourraient utiliser, des technologies et des données, pour fournir des usages numériques, alignés avec une logique d’ensemble. Toutes les applications, qu’elles soient orientées relation clients ou qu’elles servent à produire les offres de l’entreprise ou à supporter son fonctionnement ou son administration, servent in fine le modèle économique de l’organisation. Et elles ont à communiquer, de manière accessible, de l’information signifiante pour être efficaces.
Les humains ont à communiquer pour pouvoir travailler ensemble. Mais pas n’importe comment. Pour contribuer de concert aux mêmes buts, ils doivent s’entendre sur la nature et le sens des informations à partager. Ainsi, créer un système d’aide à la décision suppose avoir une idée du type de décisions à prendre et du type de questions à se poser. Sans cela, comment savoir quels éléments clés peuvent apporter des réponses? Pour que des applications soient utiles, qu’elles puissent supporter des tâches, opérationnelles ou décisionnelles, il leur faut pouvoir qualifier les éléments qu’elles auront à collecter, stocker, restituer, traiter et échanger.
à points de vue différents, vocabulaires différents
], via flickr")
Jeunes visiteurs devant l’œuvre de Miguel Chevalier : la vague des pixels (2013)
Pour gérer la complexité des échanges humains, en particulier autour des projets des systèmes d’information, des structures de coordination et de communication, de conduite du changement, des instances de décision, ont été mises en place. Elles ne font pas disparaître ce qui restera toujours, les différences de vocabulaires et de visions. Mais elles permettent d’organiser, d’optimiser et de fluidifier les échanges entre acteurs pour une confrontation enrichissante des points de vue. Le contenu des échanges sera toujours spécifique à chaque entreprise et à ses modèles. Aussi bien le modèle économique que les modèles de processus métiers.
Si le langage est différent d’une organisation à une autre, entre les métiers d’une même organisation, il l’est également. Il n’y a pas non plus de langage de compréhension universel, tout au plus une structure commune liant les vocabulaires.
Car si différentes activités traitent des mêmes objets d’information, elles ne les voient pas de la même façon. En substance, ce sont les mêmes concepts, d’un point de vue sémantique, qui sont manipulés, mais pas les mêmes propriétés. Regardons le cycle de vie d’un produit. La façon de nommer ce dernier diffère entre la conception, la recherche et développement, le marketing, les méthodes, etc. Les vues nécessaires sur les composants et les caractéristiques d’un produit/Article ne seront pas les mêmes que l’on soit en phase de maquette ou de réalisation industrielle, de vente, ou même de support et maintenance.
De nombreuses applications développées en silos
Cette différence de vocabulaires entre activités, s’est retrouvée au fil de l’eau dans les applications. Parce que souvent développées en silos, département par département. Ce qui a conduit, en grande partie, au cauchemar de l’intégration des systèmes. Une même donnée, associée à un objet d’information n’aura pas la même définition, pas la même représentation, ni les mêmes caractéristiques, ni le même format de stockage et/ou d’échange entre deux applications différentes.
Pour prendre un exemple, une adresse pourrait être un champ texte dans une application. Dans une autre, elle sera répartie en plusieurs champs contrôlés, avec contrôle du code postal, de la ville, du pays. Dès lors qu’il y aura nécessité de réconcilier les informations issues de plusieurs sources, pour questionner les ventes sur un code postal, par exemple, ou juste pour un échange d’information entre deux entités inhérent à un processus transverse, on se retrouve à devoir développer des sortes d’« outils de traduction » coûteux entre applications (développement d’interfaces, usage d’ETL, etc.). Sans parler même des problèmes de dédoublonnage dans les bases clients.
Comment mieux faire communiquer les applications?
Cette question d’interopérabilité applicative a deux niveaux. L’un concerne les canaux d’échange et la gestion des flux, l’autre le contenu des échanges, les données. L’idéal serait de pouvoir échanger de l’information entre applications sans qu’il soit nécessaire d’avoir connaissance de leur modèle de données sous-jacent, des formats de données et des technologies employés.
Même s’il est très dangereux de négliger la tuyauterie et les canalisations dans une maison, on peut considérer que l’aspect technique (tuyaux d’échange, canaux et protocoles) est assez bien couvert par des normes et technologies répandues. Cet aspect porte sur la faisabilité de la communication. En ce qui concerne l’interopérabilité sémantique et syntaxique (savoir communiquer et savoir se comprendre), c’est une autre paire de manches.
Des métadonnées pour qualifier le sens des données échangées

Exemple de métadonnées pour qualifier des contenus multimedia sur les sites wikimedia
L’objectif premier des applications informatiques reste de manipuler et exploiter des données pour restituer et/ou échanger des informations, à l’aide de langages adaptés. Pour comprendre la donnée et en faire de l’information porteuse de sens, il faut pouvoir la qualifier. C’est-à-dire la classifier et être capable de comprendre les liens de sens qu’elle peut avoir avec d’autres.
Qualifier une donnée, c’est possible avec des métadonnées exploitables par une machine qui «annotent» la donnée avec des informations significatives. Les bases de données fournissent d’office des métadonnées grâce à un modèle, une structuration des données, définissant comment les données sont organisées, hiérarchisées et liées. D’où la possibilité de les interroger par la suite. Idem pour les documents XML. Les balises (qui font partie elles-mêmes d’un vocabulaire défini et contrôlé) permettent d’indiquer le type de contenu qu’on va trouver entre elles, donc d’organiser la recherche de signifiant. On parle alors de données « structurées » par opposition à des données non structurées, contenus numériques, documents, posts, pages html, etc., qui ne permettent pas d’indiquer à un algorithme où trouver des informations spécifiques pour mieux classifier et rechercher le texte, par rapport à son sens.
Les solutions de gestion électronique de documents adressent cet aspect en ajoutant des formulaires pour associer des métadonnées, sur la base de mots clefs et de vocabulaires contrôlés, à des documents. Ainsi on peut classifier et rechercher aussi des données non structurées, en ajoutant une couche de structuration.
Pour que les applications puissent «se comprendre», en tous cas communiquer le sens des données échangées, il faudrait qu’elles partagent une couche de structuration des données commune. Quand les applications ont été construites indépendamment, sans référentiel de métadonnées, ce n’est naturellement pas le cas.
De l’échange de données à l’échange de sens, un chemin à trouver

Pendant un moment les ERP (Enterprise Resource Planning ou progiciel de gestion intégré) se voulaient une réponse à la problématique d’intégration d’applications hétérogènes. Initialement, le principe était de fournir, avec un seul progiciel, un ensemble de modules applicatifs pour tous les domaines d’activités de l’organisation et les lier avec des processus standardisés automatisés (workflow) autour d’une unique base de données centrale. Donc une seule structure, un seul modèle, pour lier toutes les données de toutes les applications. Les ERP voulaient en quelque sorte construire une tour de Babel applicative. Ils sont finalement des systèmes à intégrer parmi d’autres.
Car un ERP propose un support logiciel pour automatiser des processus standards. C’est déjà bien mais cela ne couvre pas, dans la grande majorité des cas, l’ensemble des besoins applicatifs d’une organisation. Puis, à supposer qu’une PME se satisfasse des fonctionnalités d’un seul ERP pour son SI, il suffit qu’elle fasse l’acquisition d’une autre société, par exemple, ou qu’elle ait à échanger des données spécifiques (produit ou autres) avec d’autres partenaires de la chaîne de valeur, pour faire face à nouveau à la problématique d’interopérabilité applicative. Avec l’ERP, l’organisation est tributaire du modèle de données de la solution. De ce fait, elle n’est pas maître de définir l’organisation de ses données. De plus, elle peut même être contrainte, dans l’exploitation qu’elle veut en faire, par les limites du modèle d’un éditeur. Sauf à l’étendre, mais dans ce cas, elle revient à la problématique d’intégration initiale.
Des bonnes pratiques d’intégration, mais encore des silos
le « hub » du MDM, centre de stockage des données de référence
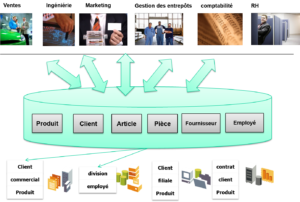
Des bonnes pratiques d’architecture d’entreprise existent, bien entendu, pour faciliter l’interopérabilité de différentes applications au sein d’un Système d’Information d’entreprise. Canaux d’échanges ou plutôt « bus d’échange », BPM (Business Process Management) avec ESB (Enterprise Service Bus) et web services, API (Application Programming Interface) standards et également MDM (Master Data Management). Ce dernier trigramme traite de la gestion des données de référence, données manipulées par les métiers (liées par exemple aux clients, fournisseurs, produits, composants, …) et éléments significatifs de l’organisation partagés par toutes les structures organisationnelles (entités, unités d’affaire, départements, …).
Le concept de MDM vise la création d’un centre de stockage des données qui gère leur synchronisation bidirectionnelle et leur réplication. Afin que toute donnée référencée par plusieurs applications soit la même pour toutes à tout moment et visible de la même façon. A cela s’ajoute différentes ressources et fonctions de modélisation, de droits d’accès, d’extraction de données sources, etc. Ainsi qu’une ouverture en terme d’évolution des modèles supportés.
Le MDM semble donc une bonne solution pour l’interopérabilité sémantique et syntaxique des applications. Reste que mettre en place une solution de MDM est un fort investissement, et en général le fait d’entreprises importantes qui ont des centaines d’applications. De plus, les solutions MDM introduisent elles aussi leur surcouche de modélisation de données et des métadonnées, le plus souvent propriété de chaque éditeur de solution. On retombe dès lors dans des silos de métadonnées et sur l’ambition d’une tour de Babel qui détiendrait un langage de structuration universel.
Et si le chemin passait par les familles de langage du web sémantique?
Du côté du web sémantique, on peut grâce à un système de métadonnées formelles, utilisant notamment la famille de langages développés par le W3C [RDF, OWL, SPARQL, ….], partager et réutiliser des données entre plusieurs applications, entreprises et groupes d’utilisateurs.
Il y a toujours là un potentiel énorme pour décloisonner les silos d’information, insuffisamment exploité (cf. l’article le web sémantique n’est plus le web de demain).
.jpg)
Et si on reliait les tours de Babel des vocabulaires, pour plus de perspective?
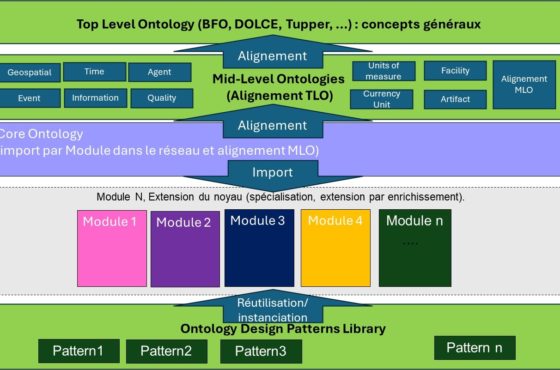
Derrière, il n’est pas question d’un langage universel pour lier toutes les informations, mais bien d’un ensemble de vocabulaires contrôlés, qui représentent formellement des champs de connaissance par des ontologies.
Une ontologie en informatique, c’est une représentation d’un domaine de connaissance, modélisé de façon à pouvoir répondre à certaines questions. Pour cela, on utilise en particulier la notion de hiérarchies de classes, d’héritage, de relations de sens entre concepts… Ce qui permet ensuite, entre autres, de raisonner sur ces concepts et d’inférer des déductions logiques. L’intérêt d’utiliser un standard comme OWL est de disposer d’un langage très expressif pour spécifier dans un langage formel les concepts d’un domaine et leurs relations, de façon compréhensible par les humains ET les machines.
On pourrait donc, avec des ontologies OWL définies par domaines d’activité, résoudre l’interopérabilité applicative d’un point de vue sémantique et syntaxique (la syntaxe d’échange est RDF/XML). Il ne s’agit définitivement pas de construire une tour de Babel unique, avec un seul langage qui représenterait l’ensemble des connaissances et des spécificités. Cette entreprise tient aujourd’hui du mythe. Mais l’on pourrait, au lieu de tout vouloir centraliser, relier les tours de connaissances par des ponts.
Des ponts entre tours de connaissance
Ces derniers sont des concepts définis dans des ontologies de référence, sorte de pierres de rosettes partagées entre ontologies d’entreprise, qui permettent de naviguer de liens en liens, de domaine de connaissances (domaine d’activité, domaine métier, domaine technique, etc.) à domaines de connaissance.
L’idée ici n’est pas de vouloir imposer un même vocabulaire à toutes les organisations, ce n’est même pas souhaitable, mais de réussir à faire des liens intelligents entre vocabulaires et garantir la provenance des données.
Cela suppose de penser autrement la conception et le pilotage des Système d’Information, avec une dimension plus collective et transverse. Il faut construire une surcouche sémantique, utilisant les standards du W3C, au-dessus de tous les systèmes de stockage de données de toutes les applications.pour pouvoir gérer un ensemble de métadonnées métiers et pouvoir interroger toutes les applications, indépendamment de leur modèle de donnés (avec SPARQL).
Pour construire cette surcouche, il y a un effort à produire, pour comprendre les concepts et les propriétés manipulées par l’organisation et pour choisir, construire et exploiter des vocabulaires partagés. Ceux qu’il est utile de définir parce qu’ils servent ou serviront aux échanges humains/machines dans l’ère numérique pour accomplir les objectifs stratégiques de l’entreprise. Pour cela il faut cesser de penser les projets au coup par coup ou voir les applications par silos d’activité et commencer par mettre en place une véritable politique d’arbitrage des investissements, fondée sur la compréhension globale de ce qui est en jeu.
En conséquence, il faut faire avancer d’abord la communication entre les parties prenantes, avant de pouvoir faire avancer la communication interapplicative. C’est ce à quoi s’attache @Semsimo, autour d’une ontologie d’entreprise, pour identifier les éléments clés nécessaires à la décision, puis en organiser le partage.