
Le Web sémantique n’est plus le web de demain
Le web sémantique n’est plus le web de demain, parce qu’il est déjà là. Mais on ne le voit pas et c’est bien dommage.
Chronique d’une mort annoncée
Fin 2016, le sujet du Web sémantique ne faisait plus l’actualité. On ne le trouvait pas dans les mots tendances de Google ou les derniers articles des technologies numériques.
Certains ne se sont pas privés d’en déduire que le web sémantique était mort. En tous cas, il aurait abandonné son statut de tendance technologique prometteuse. Il pourrait même avoir plongé dans le gouffre des désillusions de la Hype curve du Gartner. Certains disent qu’il aurait été enterré par les Linked Data, elles-mêmes supposées défuntes ou à bout de souffle. Dès lors, il serait inutile d’investir dans ses technologies et standards. Ils «n’auraient jamais marché» ou seraient «trop compliqués à utiliser» (RDF, OWL, SPARQL).
Aujourd’hui, non seulement cette pensée est fausse, mais elle est de surcroît dangereuse, dans ce qu’elle laisse s’opérer. C’est à dire une exploitation d’un potentiel énorme par un très petit nombre de sociétés en situation de monopole.
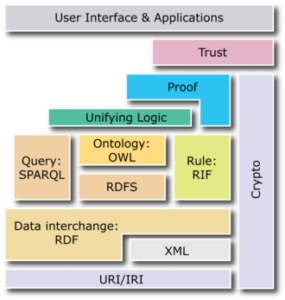
La semantic Web Stack ou la façon dont les standards du Web sémantique s’imbriquent dans une architecture globale
Le web sémantique n’est pas mort, il s’est transformé. Le premier réflexe serait de dire : tant mieux ! En effet, le web sémantique a atteint un premier stade de maturité. Il a porté ses fruits avec des standards réels et des résultats concrets. Il a réussi à sortir de sa boîte noire d’origine, avec des approches pragmatiques. Enfin, il a rejoint, avec d’autres sujets, la mouvance de l’intelligence artificielle.
Le Web sémantique a prouvé à quoi il servait! C’est clairement un moyen d’exploration et d’exploitation supplémentaire des connaissances.
Toutefois, il a montré également un enjeu de taille. La difficulté à rester ouvert, avec le biais de représentations des connaissances orientées. Il serait dommage que cette exploitation des connaissances se résume en une exploitation commerciale de données individuelles. C’est l’usage qui ressort le plus, faute d’implications de toutes les parties prenantes et en raison d’approches propriétaires des modèles.
Le vrai enjeu
Derrière le nom « web sémantique », il n’était pas question de créer un langage universel pour rendre le web intelligent. L’enjeu était ailleurs : briser les silos de données. Des automates devaient pouvoir collecter et restituer de l’information disponible en suivant des liens entre des « objets d’information ». C’est le fait de pouvoir qualifier la relation entre objets, d’une manière contrôlée, qui importait.
Cela afin que les machines puissent l’exploiter et collecter automatiquement les réponses les plus pertinentes à nos recherches de données.
La machine ne donne aucun sens à nos questions, elle n’interprète rien. Elle est juste capable de suivre des liens définis entre concepts, pour nous permettre de créer de la connaissance. Pour qu’elle soit d’ailleurs capable d’assurer la liaison et l’interopérabilité entre données, il faut la «nourrir» avec des vocabulaires contrôlés. Ce sont ces vocabulaires qui vont structurer les données, préciser leur sémantique, permettre des contrôles d’intégrité logique et des inférences.
Les ontologies au cœur des graphes de connaissance
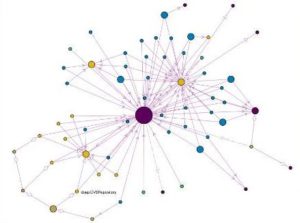
Visualisation graphique d’une ontologie à l’aide du plugin protégé Navigowl
Comment savoir que telle information à tel endroit traite du même sujet qu’à cet autre ? Comment savoir s’il s’agit du même objet d’information réutilisé dans une autre page web ou une autre application? Peut-on automatiquement naviguer de cet endroit à cet autre pour chercher plus d’informations qu’on va pouvoir transformer en connaissances? Est-il possible de déterminer automatiquement que tel objet est de telle nature, parce qu’il en a toutes les caractéristiques?
La machine ne le sait pas sans disposer de graphes de liens. En effet, il faut des schémas qui relient ces données et des caractéristiques qui les qualifient. Il faut des métadonnées et des ontologies.
Une ontologie en informatique, c’est une représentation d’un domaine de connaissance, modélisé de façon à pouvoir répondre à certaines questions. Pour cela, on utilise en particulier la notion de hiérarchies de classes, d’héritage, de relations de sens entre concepts… Ce qui permet ensuite, entre autres, de raisonner sur ces concepts et d’inférer des déductions logiques.
Une ontologie aide à mettre en réseau des objets de connaissance via des liens de sens, de composition, d’héritage. Ainsi les « knowledge graph » du Web sont des bases de connaissances combinant une ontologie et des instances de celle-ci. En effet, ils servent à constituer de gros volumes de faits sur des entités. Ensuite, on peut naviguer entre ces faits via leurs liens. Ces graphes de connaissances exploitent donc des modèles ontologiques, sur de grands ensembles de données (des « datasets »). Nous sommes dès lors plus proches de traiter des connaissances que des données brutes. Car les informations sont ainsi qualifiées, sans se soucier de leurs sources et formats grâce aux liens qui les caractérisent.
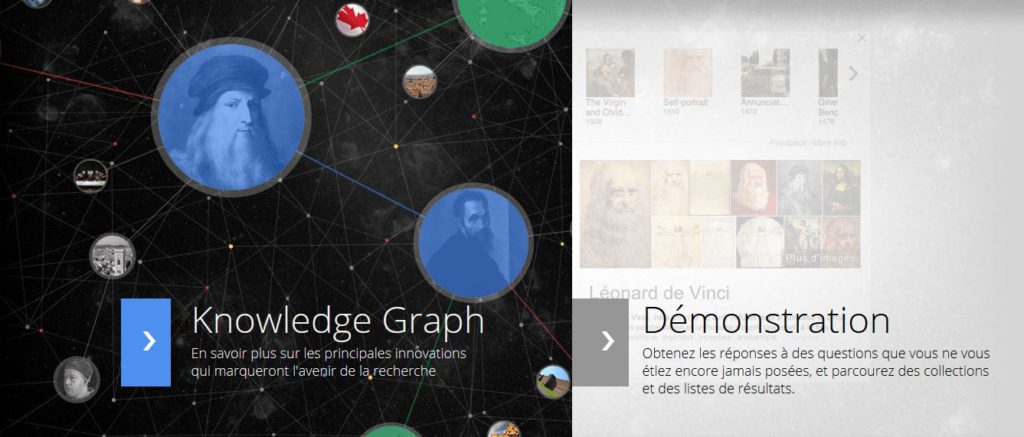
Image de la page de présentation du Knowledge graph de Google
Décloisonner les silos d’informations
Le potentiel d’exploiter de multiples sources d’information variées et qualifiées, est aussi riche en entreprise que sur le web. L’approche par les relations de sens entre les données éclaire sous un autre angle l’usage de multiples applications hétérogènes. Il s’agit de consolider des informations critiques en répondant à la problématique d’intégration entre bases de données. Quand les sources proviennent de formats très hétérogènes, il est difficile d’obtenir une vue consolidée à l’échelle de l’entreprise. Cette dernière ne s’obtient pas sans de nombreux coûts et risques dans les approches d’intégration classique de systèmes et d’applications. Placer l’intégration au niveau des métadonnées propose une toute autre perspective.

Transversalité et ouverture des systèmes ne dépendent plus des technologies, mais de la capacité à relier les données.
Les standards du Web sémantique fournissent un cadre commun pour partager et réutiliser les données dans toute une organisation. Ce partage s’inscrit même au-delà, dans des communautés professionnelles, des associations d’expertise, des secteurs métiers, etc.. Car, in fine, qu’est-ce qui est exploité, sinon l’information ? Et pouvoir dire quelque chose de cette information, n’est-ce pas la première condition pour qu’elle soit utile? Le Web sémantique, ce sont des accès aux données et une architecture pour favoriser l’interopérabilité. Il s’agit de progressivement décloisonner les systèmes d’information et encourager les données à circuler librement entre de nombreux acteurs. Ces derniers échangent de l’information au-delà d’une seule organisation. Qu’ils soient parties prenantes d’une chaine de fournisseurs, parties prenantes d’une ville, d’une société, cet échange est un enjeu majeur. Dans le domaine médical, l’usage est mondial, les perspectives passionnantes. On voit aussi des projets se concrétiser aux niveaux législatifs, éducatifs, sociétaux et commerciaux, bien entendu.
Un foisonnement de réalisations concrètes
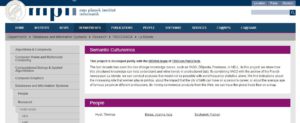
Page présentant le projet utilisant YaGo et les archives du journal Le Monde
Il y a aujourd’hui des douzaines de sociétés qui exploitent des « knowledge graph»: Apple (avec Siri), Samsung (avec Viv), Baidu, Google (Knowledge Graph bâti sur Freebase), Yandex, Microsoft (Satori, Cortana, etc.), Facebook, GE (avec Maana), Intel (avec Saffron), IBM (Watson), Amazon (avec Evi).
En plus de ces « knowledge graph » plutôt propriétaires, on peut parler d’OpenCyc, de WikiData, l’exploitation concrète de Dbpedia. Ce dernier agit en véritable point central du « Linked Of Data » en ce sens qu’il contient d’autres liens vers OpenCyc, UMBEL, GeoNames, Musicbrainz, CIA World Factbook, DBLP,1Eurostat, Uniprot, Bio2RDF et autres.
DBpedia est exploitée dans la recherche mais aussi au titre de compagnies privées. Les exemples les plus connus étant ceux de la BBC et du New York Times pour collecter, classifier, enrichir l’information. Un expérience menée avec les archives du journal Le Monde et YAgo (Yet Another Great Ontology) est assez significative. Elle a permis de relever des faits invisibles aux seules statistiques de fréquence d’emploi de verbes ou de noms. Par exemple, le rôle croissant des femmes en politique, l’impact de la ville de naissance sur la carrière d’une personne. On peut également déterminer l’âge moyen des personnes célèbres dans différentes professions. Ou suivre les flux commerciaux de produits selon la géographie….
Le secteur législatif a adopté le web sémantique
Côté juridique, on peut citer l’initiative du royaume uni, pour trouver un tribunal proche par type de problèmes, https://courttribunalfinder.service.gov.uk/api.html. L’initiative européenne du European Legislation Identifier (ELI) ( lequel va être un extension de schema.org, voir plus loin) est encore plus large. Cette initiative permet l’identification des législations au niveau européen, national et régional. Elle associe des propriétés à chaque acte législatif. Cela, grâce à des métadonnées formalisées dans une ontologie qui utilise FRBR et Dublin Core. L’intégration des métadonnées dans les sites web législatifs est prévue en utilisant RDFa.
Le barreau Belge vient de se lancer récemment dans l’affaire. Avocats.be travaille sur un projet de plateforme d’intelligence artificielle qui devrait voir le jour en 2017. Ce projet repose vraisemblablement sur des ontologies. Si on en croit la présentation de Jean-François Henrotte, avocat et président du groupe qui a travaillé sur cet outil.
Avec un tel volume de données, il faut radicalement revoir la manière de faire les choses : ne plus passer par une indexation manuelle des décisions par mot-clé mais par une indexation intelligente du système, ne plus rechercher par un mot-clé ou quelques mots la décision, la législation ou la doctrine pertinente mais par concept et une interrogation en langage naturel fondée sur le casus-même
Jean-François Henrotte
Biig Data Europe et ontologies d’entreprises
L’approche du web sémantique est également sous-jacente à la plate-forme Big Data Europe. Car une couche sémantique ajoutant sens et interopérabilité, permet de mixer les données de différentes sources à une large échelle.
Ce qui est d’ailleurs expliqué dans(cet article de Phil Archer).
Le 9 décembre 2016 a eu lieu, à Bruxelles, le second atelier autour du Big Data Europe Health, Demographic Change and Wellbeing societal challenge. Avec notamment un projet pilote qui utilise open PHACTS. Parce que cette plate-forme ouverte relie des bases de connaissances de médicaments, les chercheurs accèdent plus rapidement à des données pertinentes.
Du côté plus traditionnel des systèmes d’information d’entreprise, des éditeurs se sont rapprochés de la Global University alliance. Le rôle de cette dernière est de développer un cadre à la sémantique d’entreprise reposant sur les meilleures pratiques. SAP AG, IBM, Software AG, et IGrafx, en ont repris, d’ailleurs, tout ou partie des méta modèles.
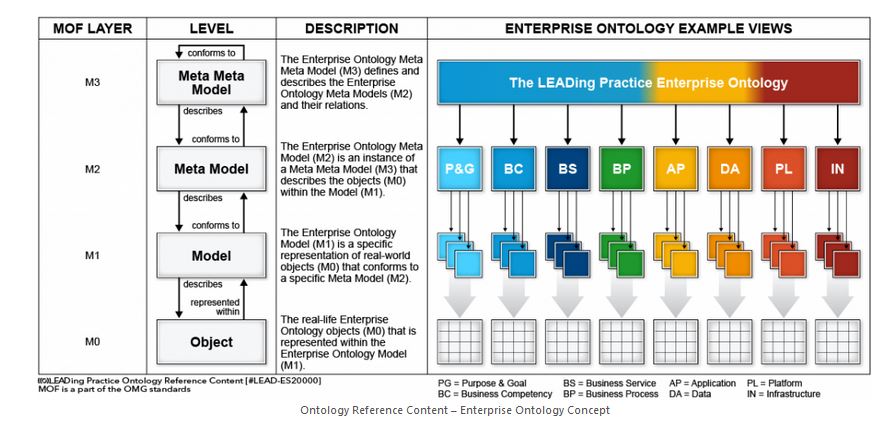
Le framework d’ontologie d’entreprise promu par la Global University Alliance
La défiance envers le web sémantique n’est pas un problème de cas pratiques.
Si la promesse est si belle et les cas pratiques existent, pourquoi le web sémantique laisse une impression si mitigée? Pourquoi le tient-on pour défunt ? Après tout, le web sémantique a tenu ses promesses. Il a délivré des standards pour créer les formats de données et les protocoles d’échanges compréhensibles par la machine. Ces standards permettent une interopérabilité hors de toute frontière de structures de données, d’applications, de système d’information, d’organisation, etc.
Certes, mais les standards ne répondaient pas forcément aux questions suivantes :
- Comment prouver l’intérêt de l’exploitation des liens sans grands ensembles de données et graphes de connaissances à interroger ?
- Si on a de grands ensembles de données, où sont-ils référencés? Où trouver une description utile pour avoir une idée précise des concepts qu’ils manipulent?
- Comment faire en sorte que les informations existantes soient annotées facilement pour être elles-mêmes qualifiées avec des métadonnées? Le cas échéant, comment trouver celles à exploiter?
- Qui va publier les données ?
- Comment s’assurer de la qualité des données publiées ? De leur origine et fiabilité ?
- Où découvrir la description des liens et des caractéristiques d’un vocabulaire ?
- Comment réutiliser sans faire d’erreurs de compréhension un vocabulaire ?
- Quel peut-être le cycle de génération et de maintenance des données dans un monde ouvert où tout le monde peut et doit contribuer ?
Le Web n’est pas une machine à laver
De larges datasets ont été vite publiés sur le Web pour fournir du grain à moudre à des cas d’usage. Ainsi brisait-on, apparemment, le sempiternel cycle de la question “qui de l’œuf ou de la poule est apparu le premier”.
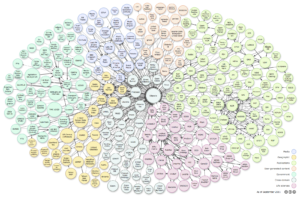
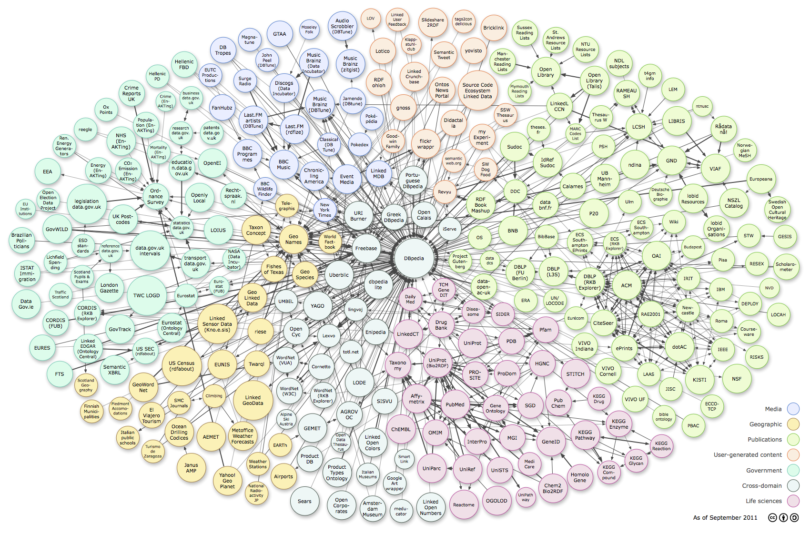
Diagramme de l’ensemble des datasets reliés dans le nuage du « Linked Of Data » en date du 2014-08-30 tel que mis à jour par Richard Cyganiak (Insight Centre for Data Analytics at NUI Galway) et Anja Jentzsch (HPI) à cette date
Oui mais … on ne partage pas les données simplement en les publiant, ce n’est pas aussi simple. On peut publier des données de mauvaise qualité, aux mauvais formats, sans parler des incohérences entre vocabulaires…
La volonté de publier vite le plus de données dans le nuage LOD était sous-tendue par une hypothèse. Celle que le web lui-même ferait son office de machine à laver des données en les nettoyant au fil du temps. Au final, ce n’est pas ce qui s’est produit. Les alignements entre concepts ou instances restent quelque chose de complexe dans un contexte où beaucoup d’incohérences subsistent entre grands ensembles de données.
Au moins, avec le format DCAT (Data Catalog Vocabulary) du W3C, il existe un moyen de fournir explicitement des informations descriptives sur les ensembles de données disponibles sur le web. DCAT permet de faciliter la découverte des datasets et leur consommation automatisée, par des agents machines. Cela autorise les applications à consommer facilement des métadonnées à partir de plusieurs catalogues. Il facilite une publication décentralisée de catalogues et la recherche de jeux de données fédérées sur les sites. Grâce à l’interopérabilité des catalogues et la création de liens sémantiques entre les données de chacun, un meta-catalogue devient possible.
Un partage de meilleures pratiques à l’heure de la maturité
Concernant la provenance des données, l’ontologie Prov-O fournit des moyens de tracer les informations essentielles dans les métadonnées qu’elle propose. Ainsi peut-on savoir qui a contribué aux données, qui joue un rôle, qui les possède, comment elles ont été générées, modifiées, etc.
Quant à la réutilisation d’ontologies Web sémantique de haute qualité, il y a les « Ontology Design Pattern ». Ce sont des patrons de conception réutilisables. Au sens où ils figurent les meilleures pratiques de modélisation pour certains domaines ou types de concepts. L’intérêt pour une réutilisation de modèles d’ontologies ciblés sur un problème et éprouvés par une communauté augmente avec la maturité du Web sémantique. Ainsi, en 2016, a été créée l’ODPA, l’association pour promouvoir les « design patterns » des ontologies.
Ontology Design Pattern portail
Le partage de meilleures pratiques de conception est accompagné par la diffusion d’outils pour répondre aux problématiques d’annotations de l’existant. Il est intéressant de se pencher sur le chemin parcouru par schema.org, qui progressivement est devenu un incontournable. Son champ d’application va bien au-delà de ce qu’en perçoivent des responsables marketing soucieux de SEO (Search Engine Optimization).
En 2013, les ontologies les plus utilisées étaient schema.org , le Facebook Open Graph Protocol (OGP), pour intégrer du contenu à la plate-forme du réseau social et le vocabulaire GoodRelation, qui définit les classes et les propriétés pour décrire les concepts de commerce électronique.
Schema.org : un moteur à deux temps?
Image du blog Schema.org
Schema.org est une illustration parfaite de ce qu’on peut appeler le moteur à deux temps du web sémantique.
C’est une approche d’abord axée sur le pragmatisme qui a fait fi des standards du Web sémantique pour revenir l’enrichir ensuite. Schema.org part d’un constat simple : si on ne connait pas l’adresse de grands ensembles de données, si on ne sait pas où commencer à chercher, qu’utilise-t-on ? La réponse est : un moteur de recherche. Et si on veut disposer de fonctionnalités de recherche intelligentes, elles ne peuvent être imaginées sans un formalisme ontologique minimal. Le but poursuivi par le schéma ontologique de Schema.org, c’est simplement une possibilité d’utiliser des balises structurées (des métadonnées) dans les contenus des pages Web pour extraire de l’information pertinente au regard de la recherche.
Schema.org est au départ une initiative sponsorisée by Google, Microsoft, Yahoo and Yandex. L’objectif est de proposer des balises de métadonnées qui soient simples d’usage pour les fournisseurs de contenus et flexibles. Le fait que l’initiative se soit opérée en dehors des standards du W3C dans un premier temps, l’a dissociée, dans les esprits, du web des données.
Pourtant, elle poursuit la même logique. D’autant que par la suite, le projet Schema.org a ajouté le support de RDFa et JSON-LD pour les annotations, rejoignant les grands principes du Web sémantique. Tandis que les communautés du Web sémantique intégrait Schema.org dans leur paysage. D’une part en proposant une version owl (fournie par topbraid), d’autre part, en proposant des extensions et des enrichissements à Schema.org dans des domaines variés.
Schema.org deuxième temps : les extensions pour le Web sémantique
Avec LRMI on peut associer des métadonnées liées à l’enseignement à des pages web/des ressources d’information, de façon à ce que ces informations soient reconnues par les moteurs de recherche.
Le vocabulaire OER Schema (Open Educational Resource) est utile pour les solutions de type LMS ou CMS. En l’employant, elles peuvent aider à inclure de nouveaux contenus dans des contenus existants, ou les référencer dans une formation, etc.
Le groupe schema bib (communauté W3C) a pour objectif d’étendre schéma.org pour améliorer le balisage des contenus et informations bibliographiques. Certes, l’extension n’atteindra pas la richesse descriptive qu’on retrouve dans le rassemblement des ontologies SPAR (Semantic Publishing and Referencing) pour tout ce qui concerne le domaine de la publication. Elle demeure un point d’entrée utile, au niveau des moteurs de recherche, pour aller chercher des informations dont le contenu sera plus qualifié avec d’autres ontologies.
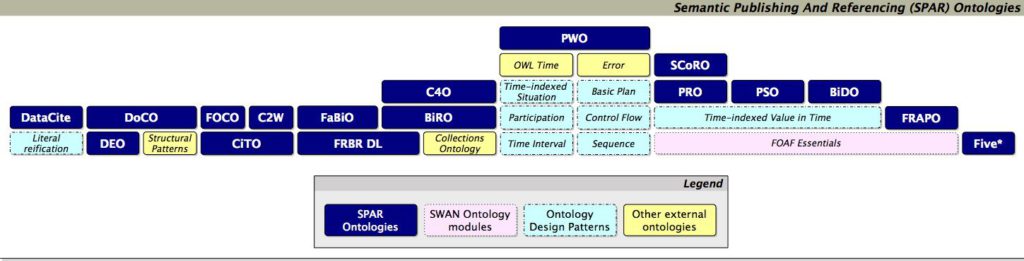
Les ontologies SPAR pour décrire le domaine de la publication
Grâce à schema.org et ses extensions il est possible de rechercher plus facilement des informations à l’aide des métadonnées qui les décrivent. Il reste à associer des métadonnées à un objet/ une page du Web.
Un « marquage » par métadonnées de plus en plus facilité
Pour cela, de plus en plus d’outils apparaissent. Par exemple, MaDaME est un outil pour aider les développeurs Web pour annoter les pages Web avec des métadonnées structurées par schema.org, avec en plus des métadonnées provenant de SUMO ou WordNet.
JSON-LD a proposé une évolution pour pouvoir plus facilement « marquer » les pages existantes pour les développeurs en se rapprochant de leurs outils habituels. Là encore, JSON-LD était au-départ une démarche pragmatique indépendante du Web sémantique, orientée pour le développement d’API. Cette démarche partageant toutefois la logique d’interopérabilité du Web des données, elle est devenue au final une sérialisation du langage RDF et une recommandation du W3C. Donc, contrairement à une autre confusion, rdf et json-ld ne sont pas opposables et ne sont pas des approches exclusives, cf cet article.
Qu’il s’agisse de schema.org ou de JSON-LD, à chaque fois les initiatives ont été saluées par certains comme signifiant la mort du Web sémantique, alors qu’elles l’ont alimenté avec une bonne dose de pragmatisme et des solutions convergeant vers les standards.
Parce que le besoin d’interopérabilité des données dépasse les querelles d’école.
Evitons de perdre le sens du Web sémantique en cours de route
Il ne faudrait pas, en se souciant seulement des querelles ou des convergences autour des outils, des méthodes, des modèles ou des formats, perdre le sens de la démarche ontologique.
N’oublions pas que l’on souhaite créer des liens de sens, exploitables par des machines, entre « objets » de connaissance. En sachant qu’un objet peut être toute sorte de choses : personne, produit, lieu, article, livre, molécule, thème de compétences, etc. Pour cela, il faut modéliser ces liens dans des domaines de connaissances, c’est-à-dire créer des ontologies.
Bien entendu, tout modèle ontologique a été construit avec un but en tête.
Le premier objectif est de disposer d’un vocabulaire commun contrôlé, hors silos, afin de pouvoir s’assurer qu’on parle de la même chose en allant chercher de l’information en dehors de ses propres bases de connaissance, à tout autre endroit accessible permettant cette recherche sur d’autres sources.
 Mais le second ? Les choix de modélisation d’une ontologie dépendent des questions auxquelles on veut répondre. Or la façon de formuler les questions ou d’expliquer quelles genres de réponses nous intéressent, ce qu’on recherche exactement, induit forcément un biais de représentation. On peut très bien vouloir interroger la répartition des richesses pour dénoncer les inégalités ou pour mieux cibler des clients consommateurs, selon la finalité de l’exploitation des données, leurs caractéristiques formalisées ne seront pas les mêmes.
Mais le second ? Les choix de modélisation d’une ontologie dépendent des questions auxquelles on veut répondre. Or la façon de formuler les questions ou d’expliquer quelles genres de réponses nous intéressent, ce qu’on recherche exactement, induit forcément un biais de représentation. On peut très bien vouloir interroger la répartition des richesses pour dénoncer les inégalités ou pour mieux cibler des clients consommateurs, selon la finalité de l’exploitation des données, leurs caractéristiques formalisées ne seront pas les mêmes.
L’utilisation de certaines représentations du monde réel pour faciliter l’accès à l’information n’est pas tout à fait innocente. Ne pas voir les impacts de ces représentations, parce qu’on les ignore, est dommageable. Cela l’est aujourd’hui et cela va empirer demain, dans l’empire des objets connectés et des interfaces.
Qui possède aujourd’hui les modèles des données ?
 Jusqu’où des données peuvent-elles être « ouvertes » ? Certes, la bataille sur la propriété des données fait rage sur le Web : Mooc, réseaux sociaux, plateformes d’intermédiation de toutes sortes, les intérêts en jeu, les enjeux des parties prenantes, sont loin d’être uniformes et questionnent les cadres juridiques, politiques, économiques et sociaux.
Jusqu’où des données peuvent-elles être « ouvertes » ? Certes, la bataille sur la propriété des données fait rage sur le Web : Mooc, réseaux sociaux, plateformes d’intermédiation de toutes sortes, les intérêts en jeu, les enjeux des parties prenantes, sont loin d’être uniformes et questionnent les cadres juridiques, politiques, économiques et sociaux.
Dans cette bataille, on oublie souvent qu’il n’y a pas que la propriété des données en cause, mais également la façon dont on les « lie » et les modèles qui président à ces liaisons
Les liaisons dangereuses …
Quand on contrôle les représentations, ou quand on les laisse se construire
Les « knowlegde graph » utilisés par les GAFAMI (Google, Apple, Facebook , Amazon, Microsoft, IBM), ajoutent aux moteurs de recherche une surcouche permettant de qualifier et mettre en relation sémantique différents objets de connaissances sur la base d’une modélisation formelle de la connaissance plutôt que sur des statistiques de mots et de meures de pertinence ou de nombre de liens entrants.
Le « knowledge graph » de Google, aujourd’hui propriétaire mais accessible et interrogeable via la Knowledge Graph API est par exemple hérité en partie de ce qui fut « Freebase ». Cette base de connaissance a été elle-même construite sur les contributions d’individus, de communautés et autre sources. Google inclue également des données en provenance du CIA World Factbook (sorte de Quid planétaire Américain). Le knowlegde graph est ainsi une énorme ontologie, mais dont on peut interroger la consistance et la qualité des liens pour en établir des inférences logiques.
Désormais, il est possible de construire des graphes de connaissances automatiquement, en extrayant les métadonnées dans les milliards de pages web (à travers du text mining entre autres), en peuplant les bases d’objets qualifiés automatiquement. L’objectif est de construire des bases de connaissances que ni des experts ni des communautés ne pourraient réellement mettre à jour à grande ampleur. Toutefois, il y a forcément des questions à se poser sur la nature des bases de connaissance que nous construisons, et sur leur exploitation.
Il y a des limites à nourrir des modèles prédictifs avec des knowledge graph en espérant pouvoir ensuite en tirer la connaissance exacte des faits, des comportements et de la réalité du monde qui nous entoure.
Tous les modèles sont faux, il y en a qui sont plus utiles que d’autres

Site factCheck.org
Il est intéressant de voir Google investir dans le « fact-checking » et se baser sur les réseaux de connaissance ou les métadonnées pour vérifier la «crédibilité » d’une assertion et la pertinence des faits. Certes, il est devenu primordial de réagir à ce qui gangrène actuellement l’accès à la connaissance via Internet. Les hoax, les fakes et la manipulation de l’information sévissent à travers les réseaux sociaux et tous les outils de publication.
Toutefois, sans tomber le moins du monde dans la théorie du complot, on peut très bien énoncer que ce n’est pas parce qu’une chose est qualifiée de la même manière par des sources différentes, que cette chose est vraie.
L’évolution des découvertes scientifiques le démontre. Il faut rester prudent dans l’évaluation de la « confiance » qu’on peut donner à une information, et ne pas négliger les marges d’erreurs, importantes, des déductions automatiques fondées sur des modèles.
Une ontologie avec consensus d’expert, ouverte, visible, ce n’est pas si mal, face à une ontologie construite sur la base de liens définis a posteriori, parce qu’on sait que la première est un consensus formalisé après discussion, alors que la seconde est un automatisme qui exploite ce qui a été plus ou moins bien échangé sur le sujet par écrit C’est un peu, en caricaturant légèrement, comme si on définissait la vérité d’une théorie, par le fait qu’elle est cohérente avec le paradigme majeur de son temps et le nombre de référents qui la soutiennent… Mais si cette théorie est vraiment innovatrice et en rupture avec les modèles traditionnels sans pour autant être fausse, sera-t-elle considérée comme pouvant être potentiellement vraie puisqu’elle est différente d’un modèle « approuvé » ?
Des inquiétudes à prendre en compte
 Nous avons à nous interroger sur la façon dont nous livrons nos données aux Google, Amazon, Facebook et autres et l’exploitation qu’ils en font ensuite pour nous diriger toujours plus vers une vision orientée du monde. Celle-ci devient restreinte à nos intérêts supposés, mais surtout ceux qui pourraient intéresser en retour d’autres acteurs (publicité, recommandations, etc.).
Nous avons à nous interroger sur la façon dont nous livrons nos données aux Google, Amazon, Facebook et autres et l’exploitation qu’ils en font ensuite pour nous diriger toujours plus vers une vision orientée du monde. Celle-ci devient restreinte à nos intérêts supposés, mais surtout ceux qui pourraient intéresser en retour d’autres acteurs (publicité, recommandations, etc.).
L’inquiétude sur la confidentialité des données privée n’est pas neuve (cf. cet article citant john Mac Affee) .Pas plus que ne l’est l’inquiétude sur l’exploitation qui peut être faite de rapprochements automatiques entre données (cf l’article sur le livre « back box society « de frank pasquale))
La propriété des données est une bataille, un accès « ouvert » aux informations en est une autre. Derrière cette ouverture de l’accès, il y a la question du sens des représentations qui sont utilisées pour nous proposer du contenu ou des produits à acheter, susceptibles en théorie de nous intéresser ou d’être représentatifs de notre recherche.
Ce sont des opportunités formidables qui s’offrent à nous aujourd’hui, mais il n’y a pas d’opportunités sans risque. Pour vraiment construire de la valeur à partir des outils et des méthodes proposés par le web sémantique, il faut aussi prendre en compte les buts réellement poursuivis et les risques.
Une ontologie informatique n’a pas à être exhaustive. En réalité, elle ne le sera jamais car elle part d’un point de vue. A quelle exhaustivité peuvent prétendre les « knowledge graph » des grands acteurs fondé sur une représentation du monde économiquement orientée?
Le monde est ma représentation disait Schopenhauer.
L’être des choses est identique à sa prise de connaissance. « Elles sont » veut dire : elles sont représentées. Vous vous dites qu’elles seraient quand même là s’il n’y avait personne pour les voir et se les représenter. Mais essayez donc un peu de vous représenter clairement ce que serait alors l’existence de ces choses. Et vous verrez aussitôt que c’est toujours une vue du monde qui vous vient en tête et jamais un monde hors de toute représentation. Vous voyez donc bien que l’être des choses consiste en leur représentation.
Schopenhauer
Le risque, aujourd’hui, est que ma représentation du monde devienne, à force de ne voir que certains liens entre informations, celle d’un autre. Par exemple, celle qu’a choisie Google, ou celle qu’a choisi Amazon. Cette dernière manipule également des KG pour pousser à des actes d’achats et concurrence inéluctablement Google sur la position de Big Brother omniscient (cf. cet article).
De plus en plus ces deux acteurs feront référence pour les recherches et l’accès à l’information. Or ils donneront toujours un aperçu de la connaissance en fonction de leurs buts. Leur vision du monde est orientée par le fait que ce sont des sociétés américaines libérales qui cherchent à faire du profit. Si leur reprocher cela est contestable, on peut et on doit s’inquiéter de voir peser la prédominance de leur vision dans l’accès à la connaissance en ligne, sans qu’il y ait contrepoids.
Comprendre que le web sémantique est celui d’aujourd’hui devient primordial pour voir le web de demain devenir autre chose que la base de connaissances de quelques grands acteurs privés. Il est temps non seulement de se soucier de la protection des données personnelles, mais aussi des modèles de représentation employés pour fournir l’accès à l’information.



L’article à beau avoir plus de 2 ans je le trouve toujours d’actualité. Bravo et merci !